
本日のイベント勉強会は、「生成AI活用の事例共有・大企業と中小企業スタートアップでの違い」というところで、今回の発表者株式会社LangCoreの北原様に事例共有の発表と弊社の事例共有の2本立てで行います。
さっそく、北原様の発表内容に入らせていただきます!
生成AIの認知度・導入への所感
まず、背景についてですが、生成AIに関する「認知度」については大幅に向上がみられました。以下の図の通り、春と秋に2回行われています。
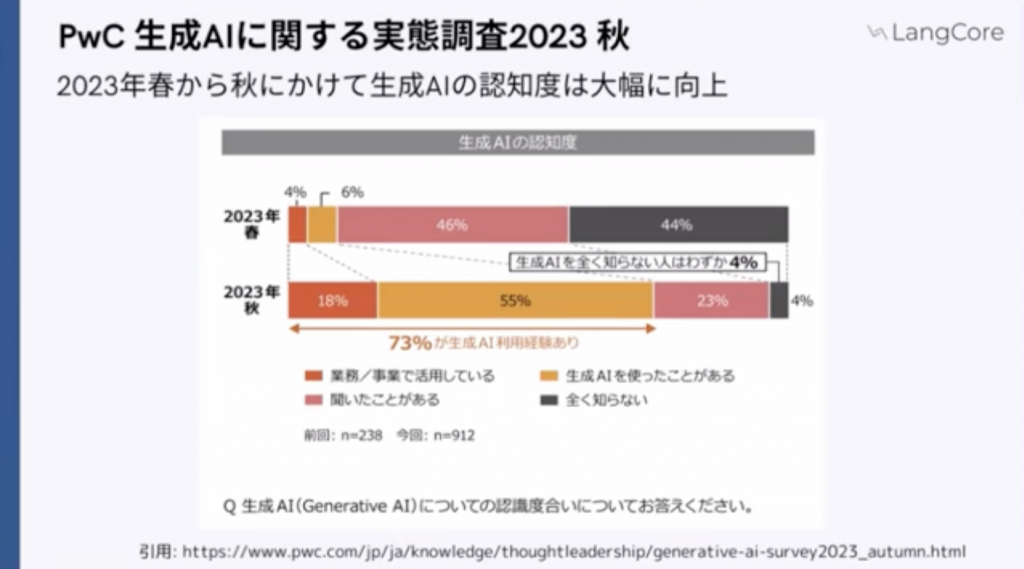
この2回で非常に数値が変わっています。上の図から以下のことが読み取れます。
・業務で活用している
春:4% → 秋:18% (+14%増)
・生成AIを使用したことがある。
春:6% → 秋:55% (+49%増)
秋には計73%の方が生成AI触れたことがあると解答
おそらく、この記事を読んでいる方々は、全員使ったことがあるのかなと思います。そして、個人個人の生産性を向上させるという目的で使っているかと思います。
一方で我々にご相談いただくクライアントの方々は、個人の生産性を向上させるよりも大きなインパクトを出そうとしている方々が多いです。主に以下3つのことを目的とし、APIであったり、ツールを使って業務改善新規上でより大きなインパクトを出すということにチャレンジしている方々がおります。
・リスキリング(生産性の向上)
・業務効率化
・新しいビジネスの作成

このようなお問い合わせをいただく中で、小規模から個人の方からの問い合わせもいただいたりして、プロダクトを作って検証するようなことをしています。
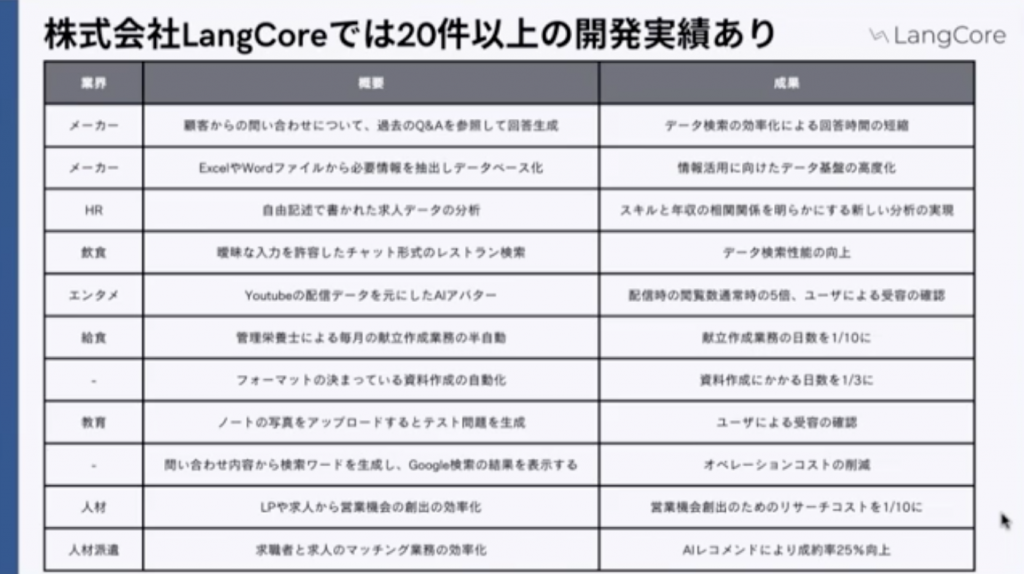
ここでは「うまくいきました」みたいなことに書いているんですけども実際やってみると、なかなか難しかったりだとかかなり苦戦することもあったりします。逆にやってみて思っている以上の成果が出たみたいなこともあったりもしました。
さらに、知見がたまってきており、大企業の方での案件等もいただき、そこで感じているところのすごい狭い範囲ではあるんですけれども僕が感じているところとしては他社から遅れを取らないことっていうところがモチベーションになっているのかなみたいなふうに感じております。
PwCの秋の調査でも同じくそのような調査結果が出ています。
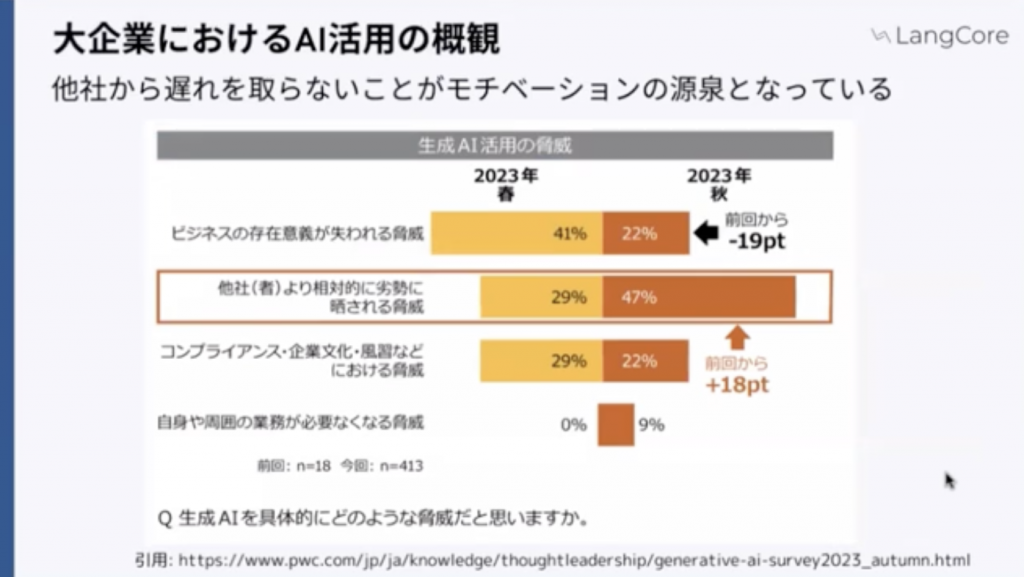
他の会社さんよりも相対的に劣勢・・・になるんじゃないかっていうところの不安感がモチベーションの原性になっているなというスタンスとしては感じております。なので、案件としても
社内ChatGPTを作成
社内データ検索
各社の正当率を検証
これらの話が多いなと感じております。

私の所感と感想にはなるのですが、
大企業
「テックドリブン」で中長期的に見据えた人材育成の側面が大きいのかなと思っています。一方で悪い面で言いますと、具体的な課題ベースではないなというところは所感としてあります。
「この課題を解決したい」みたいなものがあるわけではないため、若干不透明なまま推進されているケースがあるかなと思います。
中小企業とかスタートアップ
案件予算が限られているということがあり、そこが好循環で、かなり真に迫った課題、やりたいことが非常に明確なケースが多い方と思っています。
この辺が大企業と中小企業のスタンスの違いみたいなところを感じています。
案件創出・完遂までの流れ
実際スピーディーにやるみたいな話をしたとき、以下の図を提示しました。
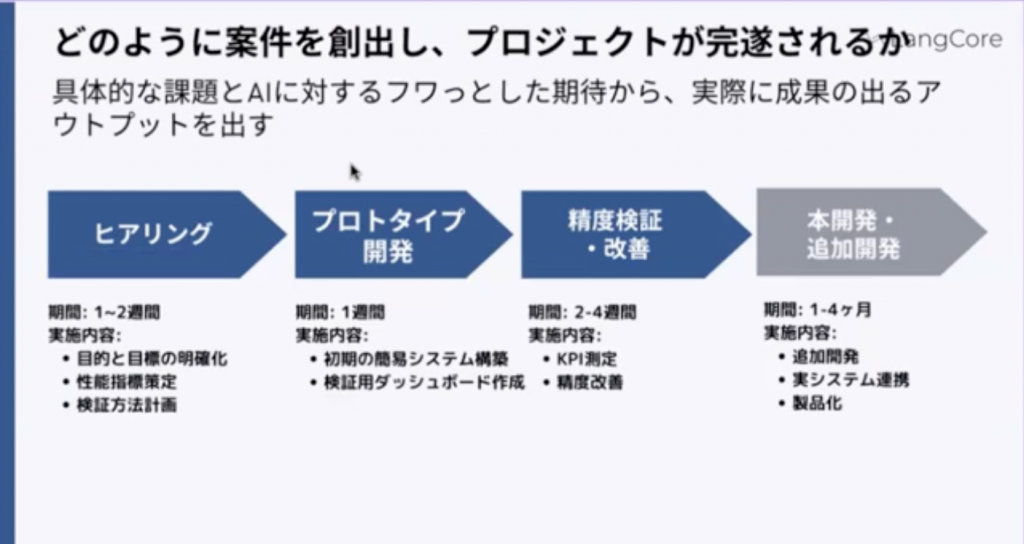
「具体的な課題」と「AIに対するふわっとした期待」これらから実際の成果が出るアウトプットを出すようなことをやっています。具体的に事例ベースで説明していきます。
ヒアリング
ヒアリングの段階で
「こんなことがしたいです」と「この業務を生成AIで置き換えたいです。」そして、実際に自分たちでもデータを用意してCodeInterpreterに投げてみました。しかし、処理が結構複雑でうまくいきませんでしたどうしたらいいでしょうか。。。。
このような相談をいただきます。実際に内容を見てみますと、
データ非常に複雑・・・複数のテーブルのリレーションのデータであったりだとかタスクというか要件も結構シンプルじゃないんでそれをこのままChatGPTに投げてもなかなか荷が重い・・・
プロトタイプ開発
上のヒアリングを元に、
「部分的に生成AIに任せられるタスク」
「機械的に処理するシステム」
これらを組み合わせることで、期待するアウトプットが出そうですねというところを設計させていただき、実際にプロットタイプを作っていきます。
そして、APIの使い方みたいなところも説明します。
分類
抽出
functioncolingを使って分岐
Embeddingを使ってテキストのベクトル化 などなど
これらを組み合わせるといろいろできるというところで、使い方がまだまだ模索しきれてない領域があるんじゃないかなと思っていたりします。
精度検証・改善
実際プロトタイプして実験してみると言語化されていなかった仕様とかが出てきます。そういうところを詰めていきますと、今まで資格保有者が2人かけて半月かけていた業務を生成AIを使って2日程度で終わるようになった。これは非常にうまくいった事例としてありました。
本開発・追加開発
さらに、それを横展開しようと、より細かい仕様の開発、システムを再設計をしていきます。
こういうことがスピーディーにできる。やっていくというところが重要なことであり楽しいことみたいなふうに思って日々業務を行っております。
より大きなインパクトを出すために協業先を募集中
僕たちができることとして、
・事例の共有
・アドバイザリー
・課題に対してソリューション検討、プロジェクト化
・開発リリース、ソース
・プロトタイプから検証まで一気通貫で伴走
いろんなことをしています。課題をいただいたら、解決するソリューションを作るっていうところは万弱にできますので、いろんな方の課題をぶつけてもらえたら面白いことできるんじゃないかなと日々思っております。より大きなインパクトを出すために協業先っていうのは常に募集しながらやっております。
少し、具体的な話がなかなかしずらかったのですけど、youtuberをAI化させたりだとか本当に色々やっておりました。以上になります。ありがとうございました。
弊社「pipon」での事例
化粧品メーカー様の事例
SDGsに対応する中で、その化粧品を作る上で、加工物を様々作らなければいけない。しかし、動物実験をしづらくなってきたというところがあります。
なので、それに対応するために化合物のデータベースを構築し、その化合物を簡単に検索できて類似の化合物も簡単に検索できて化合物と化合物を組み合わせると毒性が出るというようなアラートを出せる仕組みを作りたいというところで、そのようなデータベースを構築したという案件になります。
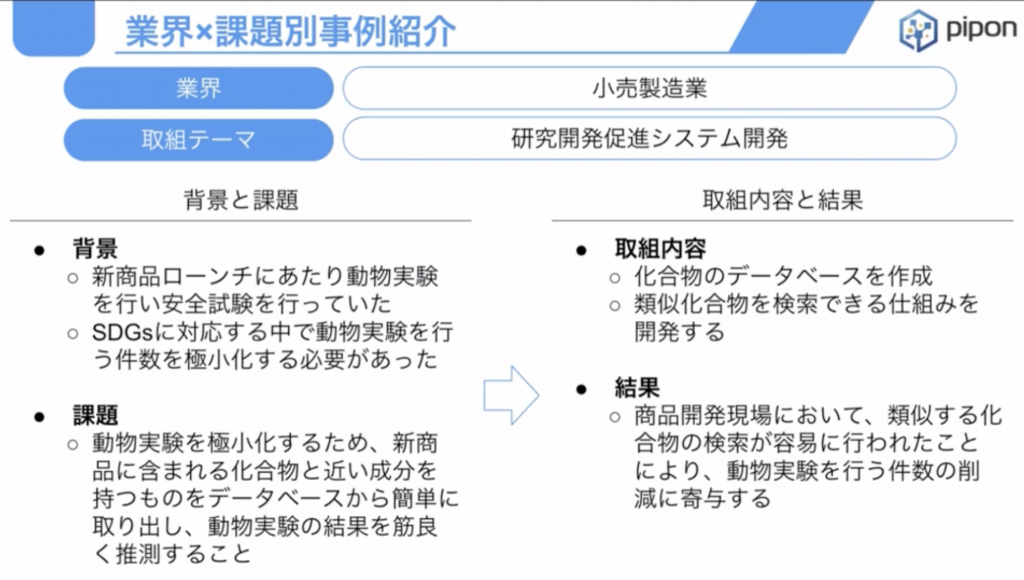
データベース作成まで
公開のデータである「PubChem」というものと「PostgreSQL」で実装していきます。
この類似の加工物を取ることや、加工物と加工物を組み合わせるときに、独占に当たるのかというところを生成AIのAPIを使ってそれをLFMに判断させるというような事例です。
GPT3.5とGPT4でもまた検証結果が違いますが、そういうような形で動物実験をしないでも化学物の組み合わせ自体で毒性のアラートが出せるということでSDGsに対応するというような案件でありました。
コンサルティングファーム様の事例
コンサルティングファーム様で社内の業務効率化をする案件であります。社内の問い合わせに対して回答するというボットを作りました。
毎月こう数千件のですね類似した質問が社内で出てくるというところで、それにスタッフが20名ほどで対応しておりました。その質問が似たような質問もいっぱい来るので、その質問対応をChatGPTにさせるというものです。
お客様の環境の中でTeamsのチャットボットを入れ、ChatGPTとつなぎ、さらに社内の文章検索できるデータベースともつなぐことで、社内の文章検索検索し、その情報をもとに回答を生成するというものです。これは、いわゆる検索拡張生成のRAGという技術を使っております。
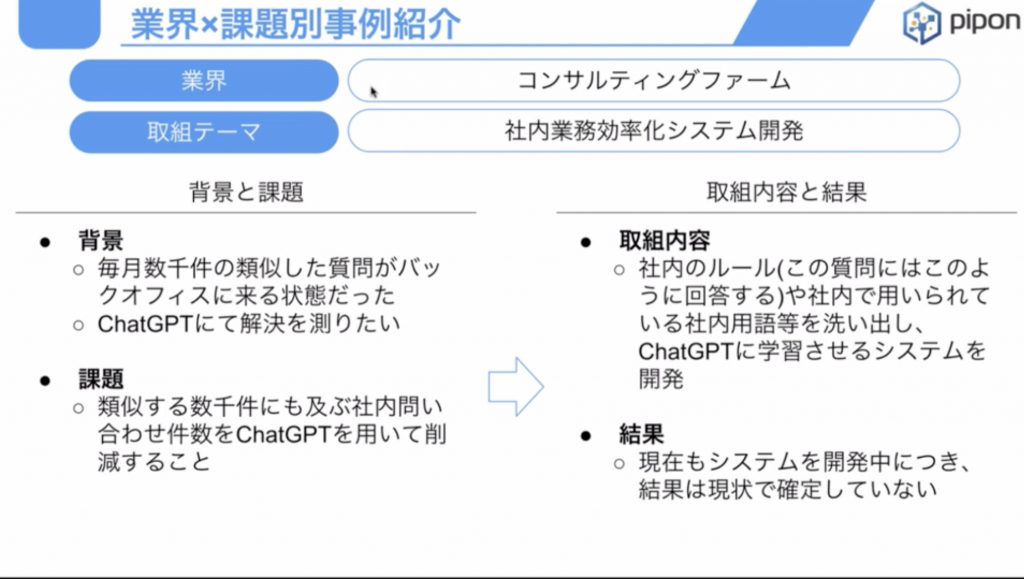
こういったお問い合わせはかなりいろいろな会社様からいただいております。(通信キャリア様、コールセンター様)また、コールセンターの中の方が社内の文書を検索したりというときに使えないかということで、今POCを進めているというような状況であります。
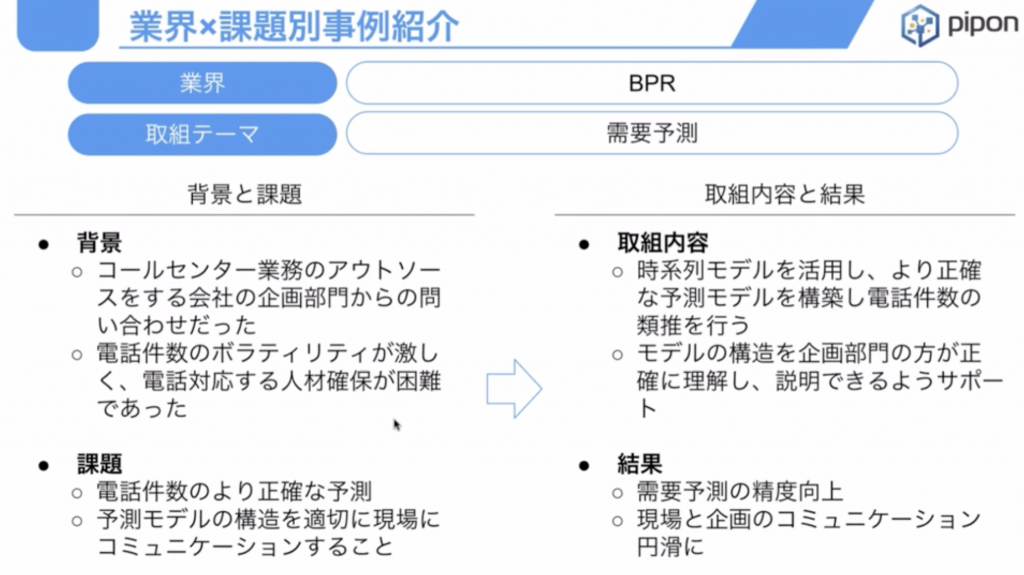
コールセンター様の事例
生成AIの事例だけではないのですが、同じコールセンター様から、「コールセンターの受電数っていうのがどのくらいになるのか」という、今までの過去のデータから解析をして、今週翌週にどれくらいの受電数が来るかという課題に、最適な人員を配置を組むための予測をするというようなことをしておりました。
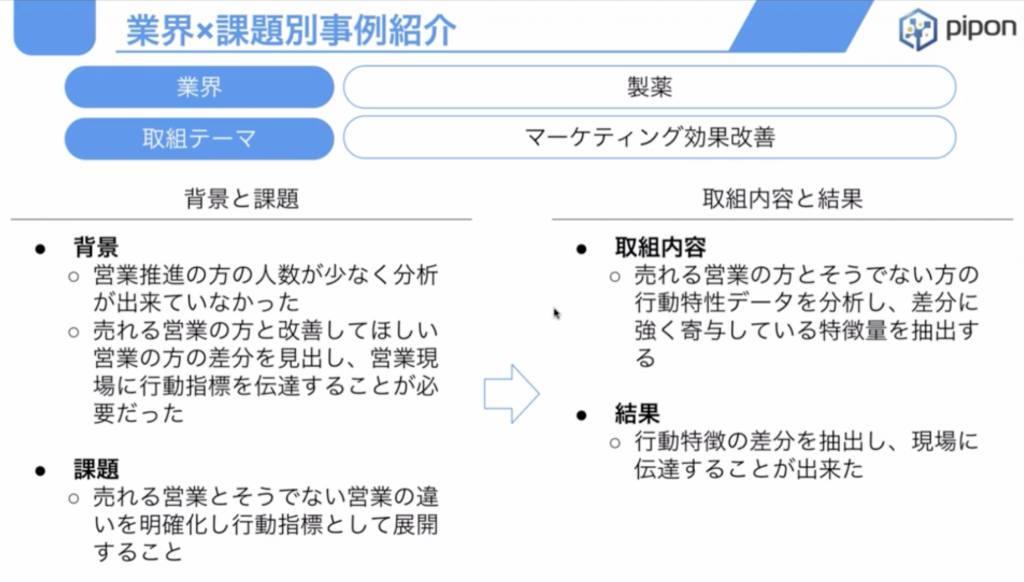
製薬会社様
製薬会社様では、様々な営業活動を行っていく中でその営業活動というのが、かなり測りづらいです。
それは一度薬を説明し、すぐに医師にその薬が採択されて処方されるには、きちんとデータを提示していきながら、臨床試験の結果とかを見せ、1年後といった長いタイムタームで営業の効果というのが出てくるものなので、営業の効果を見るというのがとても大変です。
そこで、1年とか長いタームで、「その営業活動の効果というのは、どういうところにあったか」というところをデータサイエンスによって解析をし、良い営業マンを定義するというのを行いました。
ここら辺の案件は、過去にやったものっていうところもあり、生成AIに関連はしていないところではあるんですけれども今であれば、そういったデータとGPTのCodeInterpreterというデータを解析してその結果を返すAPIもあります。
ですので、そういったところとつなげることで、さらに今まで過去やったこういったデータ解析の案件というのが簡易的にできるようになるだろうと考えております。
自動車部品のメーカー様
自動車部品のメーカー様のPOCというところで新しいカーナビを作ろうという課題です。
さまざまなデータ(イベントデータやTwitterのデータとか、店舗の口コミ情報等)をデータマネジメントプラットフォームと呼ばれるデータベースに一元管理し、そのユーザーさんが外に出たときに
周辺で良いイベントや良い店舗がある!
というところと巡り合えるようなそんなサービスを作るためのデータベースの環境構築というところをさせていただいておりました。
ここのここもデータベースの構築というところで我々のお手伝いとしては終わりましたが、そのデータから最適なイベントであったり、お店であったりを羅列してスケジュールを組むみたいなことは、ChatGPTがなかったらできませんでした。
ですが、LLMで、位置情報から評価の高いものを取ってきて、うまいことスケジュールを組んでくれるみたいなことができるようになり、こういった新しいカーナビを作ろうみたいな課題も、昔ではできなかったプロジェクトが今の生成AIの技術を使うと実現ができるようになりました。
このような形で様々な生成AIだったりデータサイエンスに関連する業務受託をしている会社でございます。簡単にはなりましたが、以上が弊社の事例にあんります。ありがとうございました。
質疑応答
Q1:ディープラーニング等の機械学習と異なり生成AIだからこそ価値が出せた具体的な事例はありますでしょうか
北原さん:今までの生成AIが出てくる前のディープラーニング等の機械学習ですと、基本的にタスクとしては予測が多かったかなと思います。特徴量と正解データを合わせた教師データを学習させて、未知のデータに対して予測をさせるみたいなことが主なタスクでした。しかし、生成AIになってからは、そこの学習データがほぼ不要、もしくはほとんど無しでも、何かしらやりたいことができるようになったところが一つ大きいです。あとは、かなり曖昧なことができるようになったなというのはあります。一個事例として、公開された求人データから、例えば、年収、必要とされるスキルということを抽出するみたいなタスクですが、今までの機械学習だと結構自由に書かれた文章からそれらを抽出するってすごく難しかったんです。しかし、生成AIに「この文章から年収を抽出であったり、スキルを抽出して」と、ただそれだけの命令でそれが実現できます。
結果的に今まで解析が難しかったような自由記述で書かれた文章を、構造的なリレーショナルデータにして分析ができるようになったみたいなことはまさにLLMだからできたことでございます。
北爪:私もまさに今までだったらその1個のモデルを作るのに大量の時間をかかってたわけですが、ChatGPTのようなモデルであれば、多くのタスクを学習せずに解けるというところがまさにイノベーションのところかなというふうに思いますのでおっしゃるとおりかなというふうに思います
Q2:スケジューリングまでLLMでできるのですか
北爪:例えばイベントであったりお店であったりというところを抽出し、このお店だったりイベントにおいてどれぐらい時間がかかるかというところを想定しながら、簡易なスケジュールを書いてくださいみたいなことを言うと、完璧なスケジュールではもちろんないんですが、簡易なものは書いてくれます。今までですと、レコメンドすべきイベントであったり、お店だったりをあげた時にそれをイベントスケジュールを組むということはできませんでした。それは、指示があやふやな要素が多く、プログラムには出せなかったし、出そうとすると、もうものすごい大変なコースになったと思います。
そういったことがプロンプト一つで、仮のスケジュールにはなりますが、ユーザーには面に見える形で、
「ここに行って、こう行ったらこういう素敵な体験ができるんだ」みたいなことを思わせることができる仮のスケジュールみたいなものが作れるようになったというところが非常に革命的だと思います。
以前、ホテルの予約サイトの会社が、ChatGPTとプラグイン連携させて、例えば友達がハワイ旅行ハワイで結婚式をするという時にその結婚式をしたついでに観光していきたいという時に、その観光プランみたいなものをChatGPTに書かせてその観光プランの中で泊まっていくべきホテルみたいなことをそのホテルの予約サイトがパッと出して予約につなげるみたいなやろうとしたことがありました。
まさに、このような形でスケジュールを書いてそこに必要な何かホテルであったり施設であったりというところを当て込んでいくということは、LLMにできるかなというふうに思います。
北原さん:次の質問等にも関わってくるかなと思うんですけれども、曖昧なことができるようになったので価値が精度が下がった可能性があるんじゃないかなど。あとは組み合わせ最適化数理最適化で定式化が難しかったものをやってくれるようになったみたいな話ですね。ここの部分はかなり過去のこういうスケジューリングとか組み合わせ最適化って定式化してあげて評価関数を最適化させるというようなアプローチを取っていたと思います。その評価関数というのが非線形で、微分で解けない場合はシミュレーション的に解いていくみたいなことをやっていたアプローチでした。しかし、生成AIでのそういうスケジューリングとか組み合わせ最適化は数式は作りません。ChatGPTとかのヒューリスティックに完全に頼ってやるみたいなアプローチになります。なので、ある種評価関数みたいなものが定義できるんであれば、そちらのほうが数理的に解けるので、精度が高いと思いますが、それが全くできないような問題に対して、生成AIでとりあえずの解を出すみたいなことはできるようになったなと思います。
北爪:ありがとうございます。おっしゃる通り、その数理最適化とか、サラリーマンの巡回理論とかですかああいうところまではあのもちろんLLMの中でやっているわけではないんですが、その曖昧というか、仮のスケジュールというところを大雑把に生成してくれるという意味で、ただ目に見えるものがあるのとないので、ユーザーの場所がレコメンドされてくるだけじゃなくて、そこにスケジュールがある。具体的に行動がイメージできるということに、価値があるかなというふうに思います。なので、そういったことが今まではできなかったなというところで価値があるのかなというふうに考えております。
Q3:文書検索やQAに活用した場合にお客様が求めていた精度はどの程度ですか例えば実際だと100%を求められてうまく進まないという話も聞きます。民間企業だとどのような感じでしょうか。
北爪:民間企業ですと、QOCというところで受託をさせていただくので、その精度も含めて検証しましょうというふうに言っております。なので全然100%を求められてっていう形では全くないですね。そこで構築して、そこで精度を見ていくということで対応させていただいております。なので、100%なんてとてもじゃないけども実現できないし、実現できると言って取ってしまうと地獄を見るので大変だなというふうに思います。
北原さん:これはジャンルによって違うんですけれども、やっぱりユーザーに出すものに関してはそうなります。精度100%近くやっぱりないと、結構そのハレーションが起きることはあります。実際にレストランの注文のタブレットを生成AIでやるみたいなプロジェクトをさせていただいて、実際にランチで活用みたいなことをしました。しかし、お店にないメニューとかをレコメンドしてしまったりして非常にちょっと問題になったりしたので、やっぱりなかなかユーザーに出すっていう観点では100%に近い精度が求められてしまいます。なので、なかなかそういうプロジェクトは難しくなりがちなので、アプローチとしては、ユーザーに出すというよりかはその裏側で、今まで人でやっていた部分を効率化させるというような文脈でまずはやってみるというところが一つよくある回避策といいますかアプローチになるかなと思います。
もう一つ、ちょっと若干変わるんですけどもエンタメ領域では全然精度求められません。先ほどAIアバターを作ったみたいな話をしたんですけども、この辺はある種あまり正しくないというか変なことを言ってもネタとして消化されるみたいなところもあったりするので、エンタメ領域ではそこの精度はほとんど求められなくて、むしろ、そういうちょっとミスをするぐらいが可愛いみたいな扱いをされたりしますね。結構こういうエンタメ領域でChatGPTを使っていくっていうところは引きも良くて面白い領域かなと思っております。
Q4:住宅へのプロジェクトとして大変なことは何ですか
北原さん:ChatGPTが言うことを聞いてくれないことはやはりあるっていうところが一番大変なところですかね。ある種、純粋なプログラムであれば、バグが出た時にそれを修正すればいいという話なんですけども、ChatGPTの場合は思った振る舞いをしなかった時に、なかなか完璧な対応策が取れないみたいなことがあって期待値とずれてしまって炎上・・・ということではないですけど、最初の期待値を超えられなかったみたいなことはあったりします。
北爪:私もちょっと思い出していたんですが、既存の技術でできることであれば、やっぱりそこを踏まえて、「何がしたいか」ということもきちんと明らかにした上でして行くのがいいかなというふうに思っておりまして、RAGで基本的に、先ほどのチャットボットを社内の問い合わせを作るというところで、チャットボットを開発をしていると、もともとがこの生成AIの性能を確かめるための案件なので仕方ないんですけれども、実際にお客様に要件を深掘って聞いていったり実際にできたものを触っていってもらうと、そんなに複雑なことを求めていなくて、チャンクしたデータをそのまま出せば別にいいというような形になったりしたプロジェクトもありました。
RAGでできることというのは、こちらももちろんご説明をして、例えばこういう「A」というものと「B」というものと「C」というものを比較して、違うところを回答するような複雑なボットが、ChatGPTで、しかも、それも社内のデータを使ってできますよ、というところなんですけれども、シンプルにその文章全体をただ出すだけでもやりたいことができたというようなことがあの起こったりしましたねっていうところであれば、既存のキーワード検索であったりっていうところの技術そのまま使えばできます。ただ、GPTの精度を確かめたいというところで、そこが目的で始まってしまうプロジェクトになると、、ちょっとそのような形で目的からずれ、本当に解決したい課題は別の手法でできたというようなこともありました
Q5:ChatGPT等のLLM系の有料のAPIを使用したシステムを構築する場合、ランニングコストが比較的大きくなるところはネックになると思いますが、実際の自宅の場でコストを抑えるためにどのような工夫をすることが多いですか?
北原さん:僕らの方は最初にSaasを作ったんですけども、その時そこにキャッシュを置きましたね。全く同じリクエストであれば、同じレスポンスを返すようなキャッシュの仕組みを作って、コスト削減みたいなことをやりました。若干ずれるかもしれないですけど、合成音声系を行う際に、ChatGPTで文章を作って、それを喋らせるみたいな時にそれをテキストというスピーチするケースがあるんですけども、そこのテキストというスピーチも結構コストがかかるんで、あらかじめ音声は生成しておいて、回答に近いものを選んでそれを再生する、みたいなことにすることで音声の部分のコストを下げるみたいなことを行いました。
北爪:私の方だとそういった事例がなくてですね、きちんと予算は取る必要があるので、例えばAzureのAPIマネジメントで誰がどれぐらいのトークンを消費していて、どれぐらいのコストがかかるであろうという予測を立てるというところは必要があるんですけれども、それを削減するみたいなところではちょっと私はまだ経験不足というところでありますね。
Q6:最近で一番面白い生成家の活用事例があれば教えてください
北原さん:そうですね、なんだろうな。ちょっと、北爪さんからお願いします。考えてください。(笑)
北爪:はい(笑)ちょっと古いっていうか、全然古くはないんですけど、GPT-4VisionのAPIを使うという案件もだんだんと増えておりまして、実際使っているんですけれども、Visionはやっぱり、すごいなというところの感想になってしまうんですけれども、今までAIOCRで画像からデータを抽出して、その取ってきた画像に対して様々な処理をするみたいなことが一般的で行われてきたのかなというふうに思います。GPT-4VisionのAPIを使えば、OCRで全部の情報を抽出するということに関しては、OCRの方が精度は高いんですけど、取ってきたデータをその意味を解釈させて変形させるであったり、何か間違いがないかということを検証させるみたいなこともセットでできるっていう意味では、GPT-4Vision1個で、画像の読み込みから情報の取得から検証まで1個でできちゃうっていうところが非常に楽しいなというふうに感じています。
そこの使い方次第で、本当にいろんな、今までいろいろな処理をかまさないとできなかったものが、とりあえずGPT-4Visionに投げるとできてしまうという世界観になる可能性はあるなというふうに思っていまして、、、まだ検証中のところなんですけども、はい、そのように思っていて面白かった!!!
北原さん:僕の方はですね。最近、面白いのはGPTsとあとはロラーですね。GPTsの方は誰でもカスタマイズされたチャットボットができるようになったんで、これは非常に応用範囲広くてすごい夢が広がるなと思ってます。各個人の今まで定型的にやってた作業とかをGPTsに最初教え込んでおけばChatGPTでもできたかもしれないけど、そこの部分を非常に効率的に1タスク1GPTsみたいな形にすることで、非常に作業の効率化ができるようになるであったりとか、GPTsも意外とやってみると奥深くていろんなことができます。画像生成させて、その画像生成させたものにPythonで文字入れしてみたいなことをして、ブログとかのキャップOGPみたいなものを作ったりだとか、使ってみるとすごく奥深いっていうのがありました。
もう一つ、画像生成系に一つ一個ロラーですね。ハマっていて、ロラーは去年ぐらいから生まれた技術だと思うんですけども当時ステイブルディフュージョンのバージョンが1.5とか2だったので、なかなかクオリティの高い画像ができなかったんですけど、今ステイブルディフュージョンもXLでバージョン上がってきていて、結構ロラーでキャラクターを学習させて出す画像のクオリティが本当に人が描いたものと見分けがつかないレベルになってきています。これはなかなか面白いんじゃないかなみたいな風に最近思っていてるので、色んな事業者さんにこんな技術あるんですけどみたいなものを持って行って、何か活用方法ありませんかみたいな話を色んなとこにしてもらっております。
Q7:発注者側が自宅AIの研修を希望されるのでしょうか、どのように行うのでしょうか
北爪:発注者側がもちろんAIの研修テストはもちろん希望されます。どれぐらいの精度でできるのかとかじゃあチャットボット作ったらどのくらいのレベルの質問にどのくらい回答できるのかというところはもちろん求められるところなので、それを検証をしております。そういう検証ツールもですね、例えば、AzureとかですとPromptFlowというものができていて、質問と回答のセット質問を流すとですね、LLMがバッチ処理のような形で回答を生成してくれて、その回答を評価するというツールになっていて、非常に作ったBotに対しての評価もしやすくなっているので、こういったツールを使って、先方にこういうものですよとプロンプトを変えるとこういう結果になりそうですとかチャンクを変えるとこういう結果になりそうですとかというようなことをしております。
北原さん:テストのほうは確実にやるべきことなので、先方から言われなかったとしても最初の段階でKPIを設定するために「このタスクの精度を上げますと、80%以上で達成します。」みたいな約束をして、プロジェクトを始めることが多いですね。そこであらかじめこのテストをやっていくというところの目標を立て、開発をしていくというようなふうに行っています。若干が、なかなか評価が難しいタスクとかもあるんですけれども、なるべく最小段階で定量化できる形でテストを設計するということを行っています。そうすると継続的な制度向上をしたいですみたいな話になってきます。制度を上げていきたいと基本的には我々はRAGを使います。こういう質問、こういうインプットが来たらこういうアウトプットを返してほしい!というところがあって、それが達成できなかった場合というのは、RAGで保管していくということが多いです。なので、管理画面とかに登録ページを作ってあげて、こういうインプットが来たらこういうアウトプットを書いてほしい!というものを登録してもらって、リクエストのたびにそれがRAGで入ってくるんで、最初の段階ではそれ答えられなかったけど、そのデータを登録したことで、回答できるようになったよねみたいな形で精度向上させる。というようなアプローチを取ります。なかなかファインチューニングとかアノテーションさせてモデル1から学習させるとかは非常にコストかかるんであまりやらないかな。
北爪:私も制度向上させるためにRAGを使うであったり、例えば、チャットボットの案件が多いので、ちょっと音の話ばかりなってしまうんですが、社内用語であるとか社内略語であるとか、そういうものが発生してくるよという時に、どうするかみたいなところで、その社内略語自体をプロンプトに入れてしまう、もしくは社内略語が来た時に、それをLLMに一般語に変換させるみたいなことをする処理をかましましょう。というようなことで、様々な方法で制度を改善するというようなところ提案しながら運用ということを実行しております。
本日は以上です。ありがとうございました。次回の勉強会は以下のリンクより確認・申し込むことができます。ぜひご参加ください!
https://chatgptllm.connpass.com/

