
はじめに
動画はこちらになります。
今回の勉強内容はChatGPTとTeamsの連携、社内の大量の問い合わせに対応するためのBot作成方法を解説しました。
ある大きい会社様の課題として、社内で発生する手続きについて大量(月6000件ほど)の問い合わせがあります。その対応への工数は大きいため、どうにか解消できないか挑戦しました。
この課題を解消する方法として、今回はChatGPTとTeamsをつかって、社内の問い合わせの一時対応として活用することができます。
技術構成も非常にシンプルです。Teamsに対するユーザーの問い合わせがMicrosoft AzureのBotサービスを経由してChatGPTにつながる仕組みとなっています。
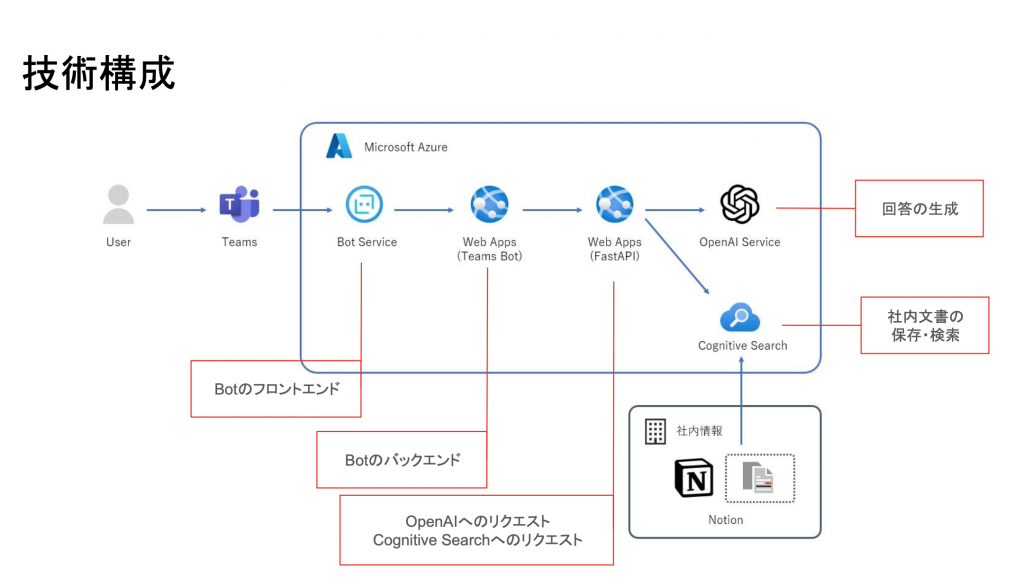
また、Botが答える内容として、弊社ではNotionにデータをまとめてあり、質問されるとそこから答える仕組みとなっています。
※下記画像の下にあるURLが答えた根拠のデータ文書になります。また、回答の正確差をはかるため、アンケートをとってログをとることで精度の良し悪しを測っております。
ChatGPT以前の自然言語処理の技術
文章(自然言語)をコンピュータに理解させるにはどうすれば良いでしょうか?
当然ですが、コンピュータは0,1でしか判断ができません。
そこで、使われていたのが、形態素解析です。形態素解析とは文を意味する最小単位に分割し、それを数値にして変換処理していた背景があります。
例えば「今日は塾に行って数学を勉強した」という文章があった場合、最初の単位として「今日/は/塾/に」といった形で分割し、重要な品詞である名詞や形容詞に絞っていました。
重要な品詞に絞った後、それを数値に変換する手法をベクトル化と呼びます。

ベクトル化の手法 ー CountVectorizer ー
CountVectrizerは、文章を単語毎の出現回数の表現に変換する手法です。
下の画像で処理の例を説明いたします。
文章0についてはappleという単語が2回出てきているので、ベクトル化する際に数値を2としております。その他も単語に応じて出現回数をカウントしていきます。

ベクトル化の手法 ー TF-IDF ー
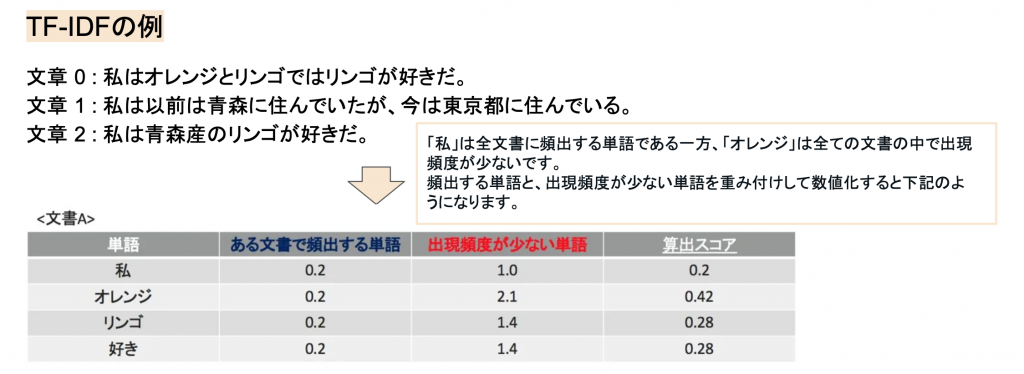
TF-IDFとは、TF(Term Frequency、単語の出現頻度)とidf(Inverse Document Frequency、逆文書頻度)という指標によって各単語を重み付けする手法です。
こちらも以下の画像を参照してください。
「私」などの頻出する単語には小さく、「オレンジ」などの頻度が少ない単語には大きく重みをつけてベクトル化していました。
この自然言語処理の問題点
かつての自然言語処理は文章をコンピュータに解釈させることは一応出来ていたのです が、問題点があります。
例えば「私はりんごが好きです」「私はりんごが嫌いです」というのは意味としては正反対のことを言っています。
しかし、単語の出現回数をベクトル化したデータでは、「好き」も「嫌い」も出現回数でしか表現されません。
そのため、文章の意味をコンピュータに解釈させることは非常に困難でした。
しかし、ニューラルネットワーク‧ディープラーニングの手法が自然言語処理でも応用されるようになってきたことで、文章の意味を数値で把握することができるようになってきました
ベクトル化 ーWord2Vec、BERT、Adaー
2017年あたりにGoogleがWord2Vecを開発しました。
文章を解析し、各単語を200次元などの数値ベクトル表現に変換する手法です。
Word2Vecのポイント
・単語をベクトル化することで、単語同士の意味の近さを計算できる。
(好きと嫌いの判断が可能に)
・ニューラルネットワークの隠れ層の重みの値を抽出することで非常に豊かな表現をすることが可能。
(※単語の足し算・引き算なども行えます。例:フランス – パリ + 東京 = 日本)
さらに、2018年にはGoogleがさらに高度な意味理解が実現できるBERT(Bidirectional Encoder Representations from Transformers)というのを開発しました。先ほどのWord2Vecは単語のみでしたが、BERTは文書を756次元の数値ベクトルへ変換することができます。
そしてOpenAIが開発したAdaを使うと文章を1536次元の数値ベクトルへ変換することができるようになりました。
こうして、文章の意味を数値として表現することが可能となり、回答精度の高いチャットボット開発をすることができるようになったのです。
ここまでのまとめ
まとめると以下の通りです。(sparse):疎ベクトル(dense):密ベクトル
- CountVectorizer(sparse)
文章を単語の出現回数の表現に変換する手法 - Term Frequency – Inverse Document Frequency(TF-IDF)(sparse)
文書中の単語の重要度を評価する手法 - Word2Vec(dense)
文章を解析し、各単語を200次元などの数値ベクトル表現に変換する手法 - Bidirectional Encoder Representations from Transformers(BERT)(dense)
文脈や文章構造を考慮した手法 - text-embedding-ada-002(dense)
OpenAIが提供しているEmbeddingモデル
疎ベクトルと密ベクトル
2つのベクトルの違いは以下の通りです。密ベクトルのおかげで、「私はりんごが好き」「私はりんごが嫌い」の意味の違いが判断できるようになっています。
● 疎ベクトル
- ベクトル要素の多くがゼロとなり、ベクトル次元が相対的に高いもの
- 例えば「準備」の語彙が i番目の要素に「用意」の語彙が j番目の要素に、別々で取り扱われるため、類義語のような意図を加味する能力に劣る
- 学習される文章中の語彙の統計情報を利用するシンプルな方法なため、ライブラリやモデルの違いが検索精度の違いにそれほど寄与しない
● 密ベクトル
- ベクトル要素の多くが非ゼロとなり、ベクトル次元が相対的に低いもの
- 例えば「準備」と「用意」の語彙を含む概念が i番目の要素で取り扱われるため。類義語のような意図を加味する能力に長ける
- 意図を加味する能力は、同様の概念をいかにまとめるかというベクトル化モデルの良し悪しに大きく依存するため、ライブラリやモデルの違いが検索精度の違いに大きく寄与する
BOT回答ができる仕組み(ベクトル検索)
テキストや画像などのデータを、機械学習モデルなどを利用してベクトルで表現し、ベクトル間の距離を計算することで、類似するベクトルを検索する手法です。
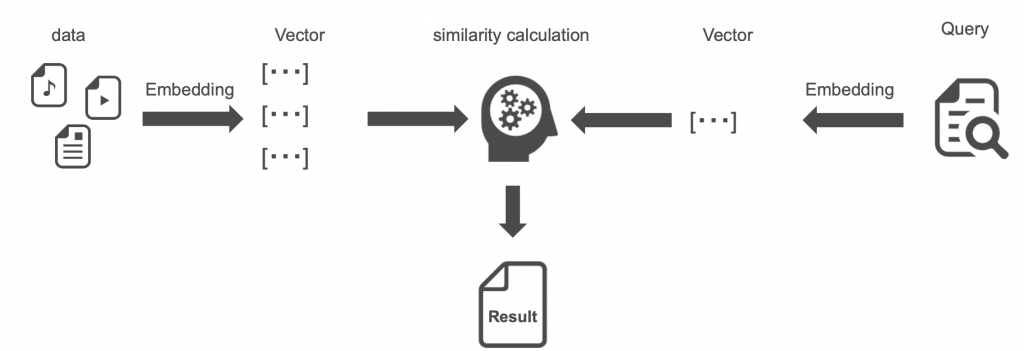
上の画像の左半分が表しているのは、元々あるデータを密ベクトルに変換しておき、そして右半分が表しているのがユーザからの質問になります。
ユーザーからの質問も同じように密ベクトルに変換をして、一番近い文書はどこか、その意図は何かということを理解して、その該当の箇所のもの(左半分のデータ)をベースに、中央にあるChatGPTが回答するということができています。
ベクトル検索の利点
往来の検索エンジンでの検索と、ベクトル検索の違いについてです。密ベクトルの特性を活かし、文章で意味を理解してくれるので、自分が求めている回答により近い回答を得ることができます。
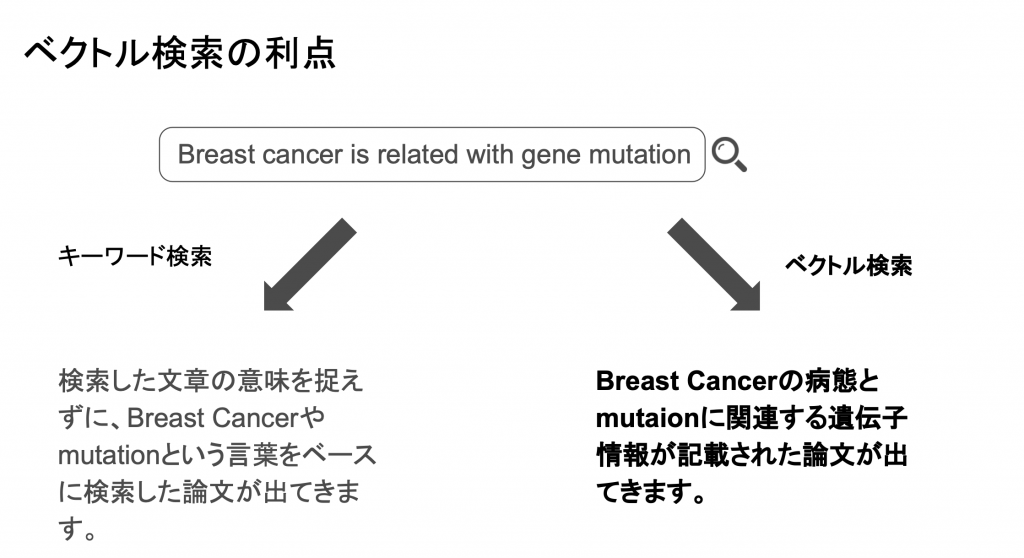
上の左の画像では、単語毎に分けて検索(往来の検索エンジン)のため、単語ベースで結果がでてきます。
ベクトル検索であれば、文章で意味が理解されているため右半分の記載の通り、より近いものが結果としてでてくるようになります。
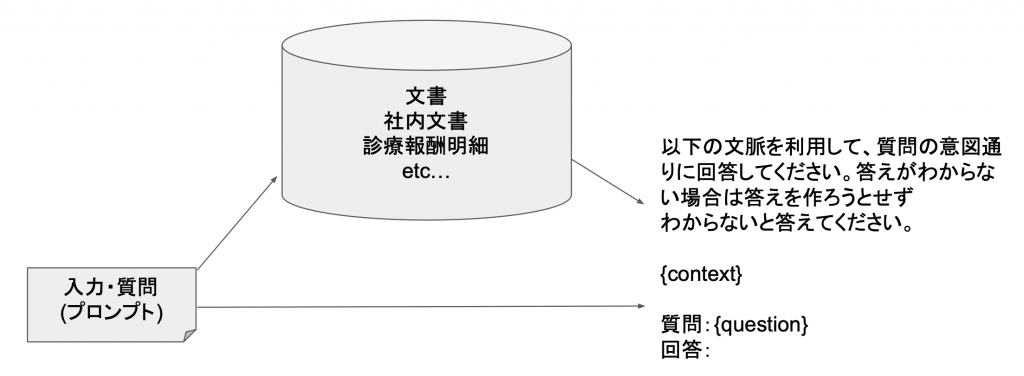
補足:RAGとHyDEについて
先ほど、上で説明した予め答えの根拠となるデータから密ベクトルに変換してVector Storeに保存しておき、入力された質問に関係しそうな文書を検索して回答するながれをRAGといいます。
しかし、入力された質問が意味がわからない時も多々あります。(我々も質問が一度で近いできることもあれば、何度か聞き返し、会話することで理解できることってありますよね)
その、質問内容を補足する手法がHyDEになります。HyDEでは、質問をもらった際、すぐに答えをつくるのではなく、一度ChatGPTの方で回答を生成し、その生成された回答を使ってベクトル化し、回答の検索のながれになります。(上の図との違いは左下部分になります。)
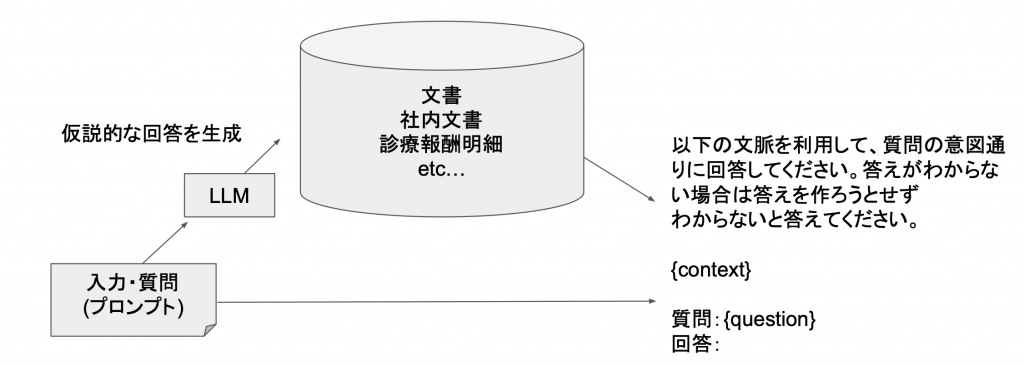
こうすることで、質問に多少の言葉数が少なくとえもChatGPTが補佐してくれますので、明確な回答が得やすくなっています。
補足2:Open Interpreterの追加機能
Open InterpreterをこのBotに追加することで、Code Interpreterを通じてデータを投げ、指示を出すだけで集計や可視化が可能になります。
Code Interpreterとは
プロンプト(質問文)でコードの生成だけでなく、実行までしてくれるツールです
今まで、コードの生成をお願いすることが主流でありましたが、それを実行までしてくれたらより便利だということで作られた機能になります。
これは私のTwitterのデータになりますが、さらに「一番表示回数が多いツイート」を集計してもらおうと思います。
回答に少し時間はかかりますが、これも可能です。
Open Interpreterを利用
Code Interpreterで実現されている機能は、Pythonと同じことが実現できます。
そしてこの機能をBotに追加することができます。Open InterpreterとCode Interpreterの2つを組み合わせることで、Teams上でより便利なBotにすることができ、データの集計や資料作成、様々な作業が容易にすることも可能です。
質疑応答
Q1.グラフのレイアウトの指定はできますか。
可能です。グラフのレイアウトを指定することができます。
具体的には、x軸やy軸の指定など、GPTに対して具体的な指示を出すことで、それに基づいてコードが生成され、グラフのレイアウトを調整していきます。それと同様に、レイアウトの指定も可能で、生成されたコードを実行してその結果を返してもらえます。ただし、GPTの解釈力に依存する部分があるので、グラフのレイアウトの基本的な指定については全然可能だと思います。
Q2.検索の元になる情報はどうやって登録していますか。
私の会社の社内の文書はAzureのCognitive Searchというサービスを利用して保管・検索をしています。これにより、SharePointやPowerPoint、PDF、ServiceNowなど、多種多様な形式の社内文書を整理して入れてあります。
”整理”について
社内文書の形態は様々であり、例えばPowerPointやExcel、PDFといった文書が蓄積されています。これらのデータをCognitive Searchに統合する際には、各文書形式に応じた整形が必要です。例えば、PowerPointであればテキストデータを抽出し、Excelであれば1列目や1行目が空いていると変な風に解釈される場合があって、それを処理するのが必要です。このような整形処理を施した上で、Cognitive Searchの中にデータを入れる必要があります。
社内チャットボットを開発する際には、最初は特定の文書に限定して開発することが良いと思います。例えば、PDFだけで文書の検索を行いたい場合は、すぐにCognitive Searchの中にデータを入れ、ボットを構築することが可能です。これにより、ボットの精度や機能を段階的に確認し、展開していのが良いと思います。
Q3.RAGはLangChainを利用して実装しているのでしょうか。
我々はLangChainを利用して実装しております。やはりこのRAGというものが、LangChainを使うことでかなり簡易に実装できるというところがございまして、LangChainを我々は利用しております。ここで出てきたこの文章の参照元(社内文書をNotionでまとめいるリンク先のこと)も取ってくるというようなところもLangChainを使えばかなり簡単に、ですね開発することができますので、LangChainを活用してRAGを使って開発をしております。
Q4.グラフを型化して同じグラフを何度もつくれるのかなときになっていた
型化して同じグラフを作るということは十分にできるかなと思います。例えば、x軸がこういう軸にしてほしい、y軸がこういうふうにしてほしいといった要望がある場合、グラフをPNGだったり画像で出力するときにはこのサイズ感で出してほしいとか、様々なルールがあるかなと思います。ただし、そのルール自体もプロンプトと同じように、保存しておいてその同じようなプロンプトを出して、データの構成は同じで中身だけが違うというようなものであれば、グラフを型化して同じグラフを何度も生成することは可能だと思います。
Q5.勤務先の社内資料は社内サーバに保存されています。LLMが解凍する根拠資料として提案してくれますか。
社内サーバーに保存されていて、その社内サーバーの例えば、社内サーバーがシェアポイントだったとしましょう。シェアポイントだったとして、この資料がこのURLで保存されているというものがあると思います。そうすればその資料とこのURLのデータというものをセットでCognitive Searchの中に入れてしまいます。そうするとこの文章はこのURLで提供されているというところをユーザーの意図通りに検索をしたときに該当箇所を取ってきたときにそのURLをメタデータとして持っていますので、この回答を生成したときはこのURLとこのURLとこのURL、この文章とこの文章とこの文章を元に回答を生成しています。ということでメタデータの情報をこのような形で文章、このような形で回答生成元の情報ということで提供することができますので、社内サーバーに保存されていてもLLMが回答する際に根拠資料として提示することは可能でございます。
Q6.Cognitive Searchの検索方法は何を使用していますか
Cognitive Searchの検索方法は様々で、アルゴリズムが存在します。単純にベクトル検索だけでなく、検索結果をランク付けし直すリランク方式も採用されています。Microsoftのコミュニティの掲示板には、このリランク方式が回答の生成において効果的であるとの情報が書かれています。したがって、我々はこのリランク方式を活用して、単純なベクトル検索だけでなく、ベクトル検索の結果をリランクして最適なランキングを得るような手法を採用しています。
Q7.データベースはどれを選定しらたいいでしょうか。
ベクトルデータベースには、様々な種類があります。例えば、PineconeというサービスやAzureのCognitive Searchなどが挙げられます。どれを選ぶかは状況によると考えており、弊社ではPineconeやCognitive Searchを使用することがあります。Azureの環境を使いたい場合、OpenAIのAPIを直接叩くのではなく、MicrosoftのAzureで既に導入済みの環境を利用することでセキュリティ上の懸念が軽減されます。特にセキュリティが気になる場合、Azureで開発することが選択肢になるでしょう。逆に、OpenAIのAPIを直接使用する際は、セキュリティ上の心配が少ない場合が考えられます。開発のしやすさや制約条件によってデータベースの選択が変わると考えています。
Q8.Teamsのチャットボットを作成する際、Teamsのアプリから引っ張ってくる方法
Teamsのチャットボットを作成するためには、AzureのサービスであるBot Serviceを使用しています。Bot Serviceを使うことでTeams上にボットを開発できます。そして、作成したボットにはFast APIでAPIを接続し、文書を検索したり、Azure Open AIのAPIを叩いたりする構成を採用しています。従って、TeamsのBotを作成するにはAzureのBotサービスを利用する必要があります。
Q9.ChatGPTに慣れてしまっているこの間に解答が返ってくるのが遅いと感じている
そうですね、ChatGPTに慣れている方は回答の速度において、現状は少し遅いと感じることがあります。これは、OpenAIのGPT APIを単純に叩いて返答しているのではなく、まず社内の文書を読みに行って、その文書を元にGPTが回答を生成しているためです。つまり、単純な質問応答ではなく、文脈を理解した上での回答生成が行われているのです。この処理の構成により、レスポンスに時間がかかる傾向があります。ただし、この手法により、より複雑な質問にも対応でき、人が人に質問して回答するよりも速い回答速度が可能です。なお、処理の構成によってレスポンスが遅く感じられることがあるものの、人と比較すると早い回答が得られるかなと思っています。
Q10.Fast APIは自分で実装する必要がありますか。
はいFast APIは自身で作成する実装する必要があります。今回のシステム作成手順の資料はありません。
Q11.AWSやGCPを選択しなかった理由はLLMの精度を最優先したからですか。
ChatGPTを使ってっていうところのオーダーがあったっていうところもあるんですけれどもそうですねAWSですと今だとクラウドというクラウド2というものがベッドロックというサービスをAWS展開しております。
ベッドロックで同じようなサービスは開発可能だと思います。クラウドの精度というのもChatGPT4と比べたときに、どれだけ精度が高いのかというところの比較はかなりクラウドもですね、ちゃんとGPT4に迫っているというようなところもあります。
けれども、一応今のところGPT4が最も精度が高いのかなっていうのと、様々な、この間のDev1.5でも発表されたように、APIが様々な機能が使えるようになったりとか、トークンの量も増えたりとかまだまだありますので、今のところでいうとわざわざベッドロックを使わなくてもいいと思っています。
ただ、AWSで構築しているっていうAWSでもう既にシステムサーバーがあってそれをA zureに引っ越すのがめんどくさいというのであればベッドロックを使うことも十分検討にあげているんじゃないかなというふうに思います。GCPを使う場合はちょっとそうですね。 GoogleがBirdを出していますが、Birdはそこまでというか、ChatGPTだったり、クラウドと比べると、このRAGを使ったチャットボットを構築するという上ではまだまだ選択肢にはならないんじゃないかなというふうに思っております。
Q12.プレゼン資料を共有していただくことは可能でしょうか。
アンケートにご回答いただいた後、送付させていただきます。
本日もありがとうございました。

