
はじめに
先日開催された本勉強会は、AI技術の最前線に位置するGPT-4 Visionの機能とその活用例に焦点を当てました。
今回特に着目したのは文章と画像とのやりとりができることになります。
GPT-4 Visionの核心的な特徴
GPT-4Vにはさまざまな特徴がございます。項目を4つに絞り、紹介していきます。
- 1. 画像とテキストの同時解析
- GPTで検索をかける時に、テキストに加え、画像も使って質問を投げることができます。これにより、文脈を持った詳細な分析が可能となります。
※ただし、「Chat-GPTプラス」に加入かつ、以下の画像のように、写真を投稿する欄がある方のみ使用できます。
- GPTで検索をかける時に、テキストに加え、画像も使って質問を投げることができます。これにより、文脈を持った詳細な分析が可能となります。
- 2. 多言語と多文化の理解 :
- こちらも画像を使って「入力/出力」が可能です。手書き文字に近い崩れたフォントについても正しく理解し、多言語に対応しております。これはグローバルな使用を意識したモデルの証左とも言えるでしょう。
- 3. 状況認識 :
- 常識に基づいて推論を行うことができます。
- 例えば、ある画像で着用している服装から結婚式であるかどうか、部屋のレイアウトから気候や家主の特性を判断する際にもその能力が発揮されます。
- 常識に基づいて推論を行うことができます。
- 4. 感情の理解 :
- 人間の感情を持つ画像の解釈にも対応しています。
GPT-4 Visionの具体的な活用例
- 画像とビデオの説明 :
- ⇨複雑なシーンでもその状況や背景を正確に文章で説明ができます。
「この画像は何をしていますか」などの問いかけに対応しています。
- ⇨複雑なシーンでもその状況や背景を正確に文章で説明ができます。
- 物体の位置の特定 :
- 詳細な物体の位置や種類を識別。
スプレッドシートを例として、セルの位置を特定し、座標で返してくれる。精度が高めだと感じている。(※以下に補足があります。)
- 詳細な物体の位置や種類を識別。
- 文章や記号に基づいた推論 :
- 例:画像中のテスト問題の解釈など。
実際にテストを読み込ませ、解いてもらい、推論することも可能。
- 例:画像中のテスト問題の解釈など。
- 生成AIの出力の改善 :
- 画像解析をもとにした新しい画像の生成。
「画像⇨説明⇨さらに画像を生成」といった無限ループようなやりとりも可能。(※こちらも以下に捕捉があります。)
- 画像解析をもとにした新しい画像の生成。
GPT-4Vの制限
テクノロジーの倫理的な側面から、特定の情報の出力制限があることを明らかにしました。
・身元情報の特定
⇨人物の画像を投稿して特定することなど。
・機密情報の窃取
⇨社会秩序を乱すような行為(犯罪のやり方など)、年齢や人種など
・根拠のない推論を招く幅の広いクエリ
⇨「この〇〇についてアドバイスをください」など
補足1:スプレッドシートでの応用例
GPT-4 Visionを用いることで、画像からのスプレッドシート操作の提案が可能となり、作業の効率化が見込まれます。
今までは、人間の頭で考えて「これに近い関数はないか」と文書で詳しく考えて質問しなければならなかったが、画像を使うことで、より簡単に質問ができるようになります。

上の図のように、質問をするだけで、そーとのやり方や関数の出し方など、具体的な手順が返ってきます。
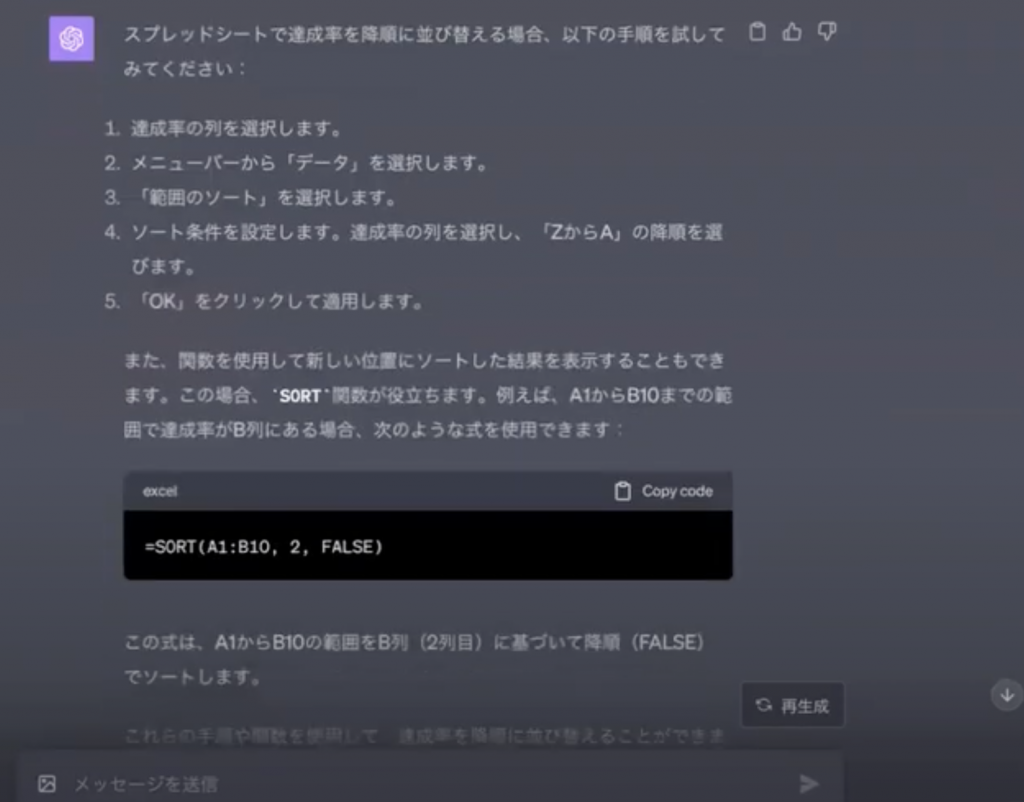
このやりとりに、私は多大な可能性を感じております。なぜなら、エクセルやスプレッドシートには多大な機能があるにもかかわらず、使いこなせていないという人が多いのではないでしょうか。

この作業したいんだけど、どんな関数や機能を使えばいいかわからない…
そんな場合でも、具体的にやりたいことを画像をつかって質問することで、解決することができるようになります!
補足2:AIによるコード生成
画像からのHTML/CSS/JavaScript生成、さらにはインフラ構成図からのテラフォームコード生成など、開発の効率化への応用が紹介されました。※こちらはまだ不完全でした。
例えば、計算機アプリを作りたい時に、出来上がりの画像を使ってHTML/CSS/JavaScript生成するような質問を試してみました。
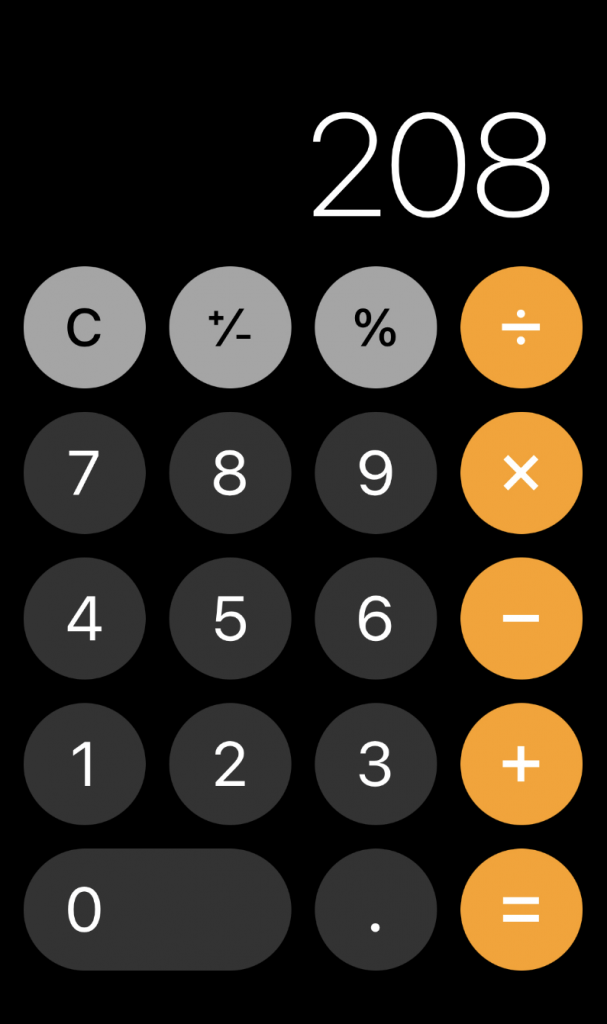
しかし、結果は見本の画像とデザインが異なっていたり、計算機のボタンが押せなかったりと、一発では完成させることができませんでした。
しかし、質問のやり取りを繰り返す中で完成へと近づけることは可能でした。

入力は可能となりましたが、まだまだレイアウトが下手だったり、色が塗られていないなど、不完全なところが多いですが。こちらも今後の発展に期待ができそうです。
補足3:画像解析の進化
「画像⇨説明⇨さらに画像を生成」といった無限ループを試してみました。「DALL-3」を使って画像の生成を行ってみていますが、正直微妙でした。。。

今回はこちらの画像をつかって「競走」のイメージを生成しながら何度かためしてみました。


サイズの変換も可能です。以下は「16:9に変換して」と投げかけました。

自分のイメージを元に生成を繰り返すので、的確なゴールがみえないことが難点です。デザイナーでない私にとって、文書をもとに生成してくれることについてはありがたいです。
補足4:インフラ構成図からのテラフォームコード生成
まだ試せていないのですが、システムを作る際に、データをどう処理して、どうデータベースを用意するかを可視化するために、以下のような構成図をつくる必要があります。
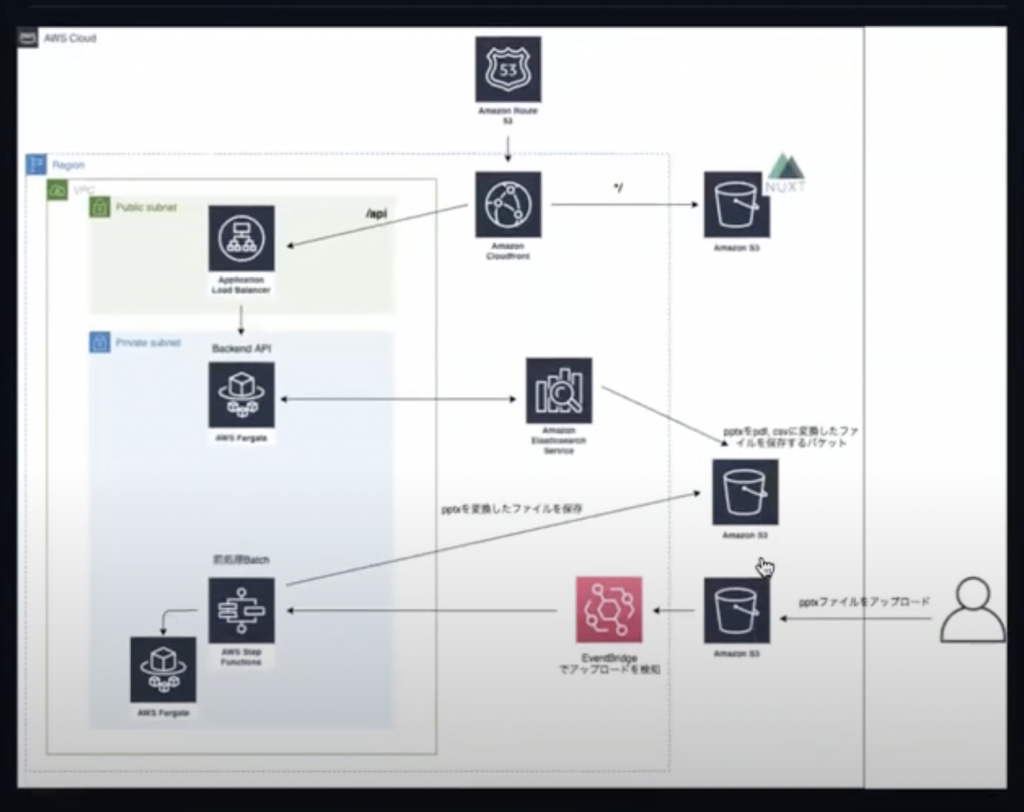
ファイルを置く場所を定義するコードを一つ一つ確認して作っていくことがかなり手間です。
上の図はかなり複雑なのですが、シンプルなものであれば生成することができることも確認ができました。工数の省略化が可能となりそうです。
補足5:グラフからデータが可能!?
データからグラフは需要はありますが、その逆についてはあまり需要がないと考えていたのですが、「市場環境」は公的なデータであることから、自社でもそのデータを使って別のグラフにしたいなと思うことがあります。
その際、グラフを一からつくる必要がありますが、GPT-4Vを使ってグラフからデータを抽出することでその手間を省くことができます。
著作権上、グラフの画像をそのまま使うことはできませんが、上記のような工程を踏めば問題なく、利用することができます。
GPT-4Vが使えないと思ったこと
以下の項目についてはGPT-4Vを用いても使えないと感じた点になります。
・ホームページのLPの改善
・領収書の読み込み
・グラフの解析
LPの改善
以下の画像は弊社のHPになります.
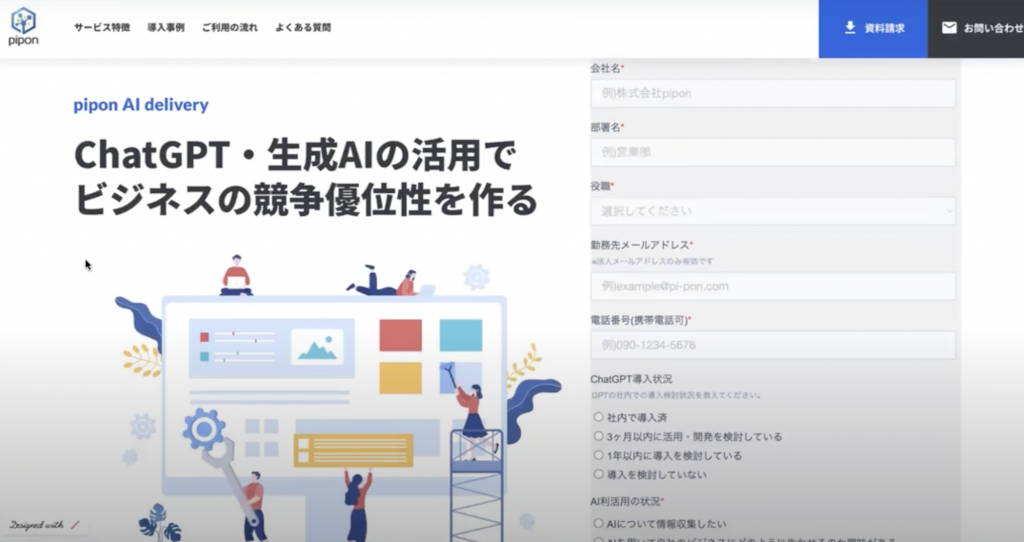
例えばですがこちらのサイト改善のためのLPを質問しても、一般的な提案はしてもらうことはできますが、マーケターの方が行うような提案をしてもらうことはできません。
領収書の読み込み
画像の質や光加減によって精度が変わってくるため、正しく読み取ってもらうことができない場合がまだ多い。プリンタなどでスキャンしてから読み取らせる手間がまだある。
グラフの解析
グラフの画像を読み取らせることも可能ですが、そのグラフが表している背景情報まで考えさせることはできません。
まとめ
GPT-4 Visionは、その高度な機能と多岐にわたる活用例を通じて、AIの可能性をさらに拡大しています。今回の勉強会で、その深い洞察と未来への期待を共有できたことは、参加者にとって大変有意義だったと感じられます。
このイベントレポートが、GPT-4 Visionに関する理解を深める際の参考となれば幸いです。

