
今回はデータインフォームドの西岡さんにLangChainを使ったデータロードについてご講義いただきました。その勉強会の内容となります。LangChainについてより詳しく、仕組みについて解説していただきました。
西岡さんは大学院時代からスタートアップの経験があったり、今でもスモールビジネスとしてデータ解析であったり、LLMを使ったプロダクトの開発を行っていたりしております。
また、Youtubeでスタートアップの話や機械学習の社会実装勉強会というのもやられております。
https://www.youtube.com/channel/UCpiskjqLv1AJg64jFCQIyBg
もし、今回の紹介で詳しく知りたい部分だったり、わかりにくい箇所があった場合にはこちらのYoutubeの動画についても見ていただければと思います。それでは始めていきます。
LangChainとは
LangChainとは言語モデルを利用するたアプリケーションのためのフレームワークのようなものになります。
ChatGPTなどの大規模言語モデルを簡単に使えるようにしたものになります。
こう聞くと、すでにOpenAIが出している、APIを叩いて使うのと同等ではと思うところではあるのですが、LangChainにはエージェント機能であったり、Vector Storeとかをうまく使うよう、またはVector databaseという検索などをうまくやるような仕組みというものがライブラリの中に組み込まれています。そして、これが外部のリソースとの連携が非常にやりやすかったりします。
他にも利点として、このエージェント機能により、テキストデータ以外のデータソースも含め、WebデータやPDFデータなども扱いやすくしてくれたり、大規模言語モデルが苦手な作業である、他のシステムとの連携というのもしやすくしてくれます
・テキストデータ以外の色々なデータソースを扱いやすくする。
・LLMが苦手な作業を他のシステムとできるようにする。
・長文の取り扱いを可能にする
他にもTemplate、Text Embedding、Cachingなどさまざまな便利機能を備えている。
実際にアプリケーションを開発しようとしたときにぶち当たる壁のようなものをどんどん超えて行くような機能が用意されているのがLangChainと理解してもらえたらなと思います。
なぜ、LangChainを使うのか

それはトークン数が関わっております。
ChatGPT3.5では4Kとか16Kののトークン数になります。そのため、日本語で渡すとトークン数が大きくなってしまい、、思うような回答が得られなかったりもします。
このトークン数の制限を超えたりしてしまうと、論文をわたして、論文の内容を聞いたりしても、思うような内容が返ってこないこともあります。そんなときもLangChainの機能が使えたりします。
少し主題とはずれてしまうのですが、論文等の長文を分散処理するような機能だったり、トークンが長い場合には、トークン数を分割してChatGPTが扱いやすいような形に分散処理する仕組みとかも可能です。
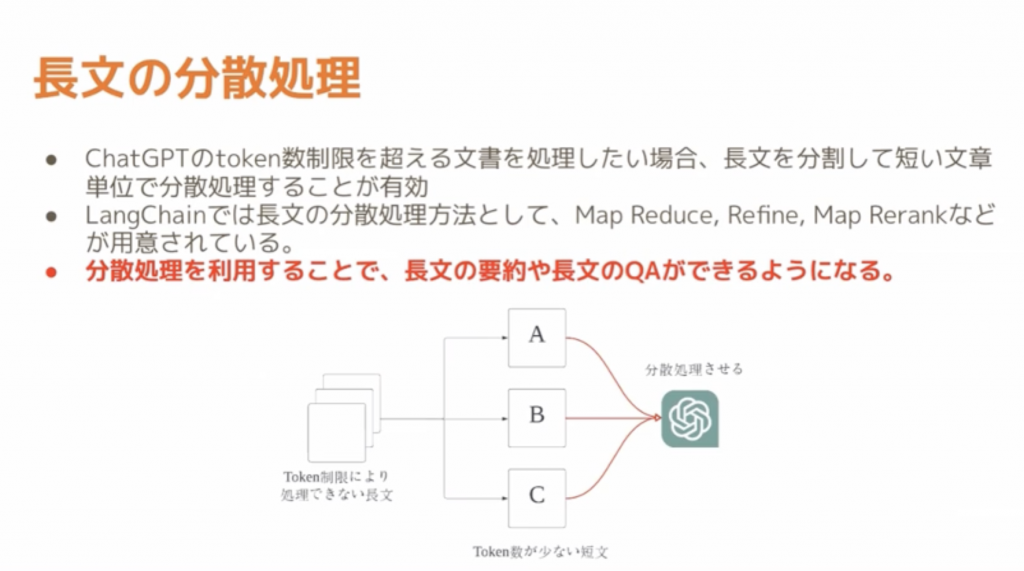
LangChainのDocument Loaderについて
このDocument Loaderというものを使って、ChatGPT以外がもっているデータソース以外のものを使えるようにします。そのために、外部のデータソースと連携するということをしていきます。ChatGPT自身は既存の学習したモデルデータしか持っていないということがあり、学習データにないようなデータを渡してしまうと変な答えを出したりと、問題が起きたりします。

Document LoaderとはPDF、Webページといったデータがまとまっているドキュメントを読み込ませる機能のことです。そしてLangChainにはこのDocument Loaderが100種類以上存在します。
実際にサイトをお見せすると、この部分になります。
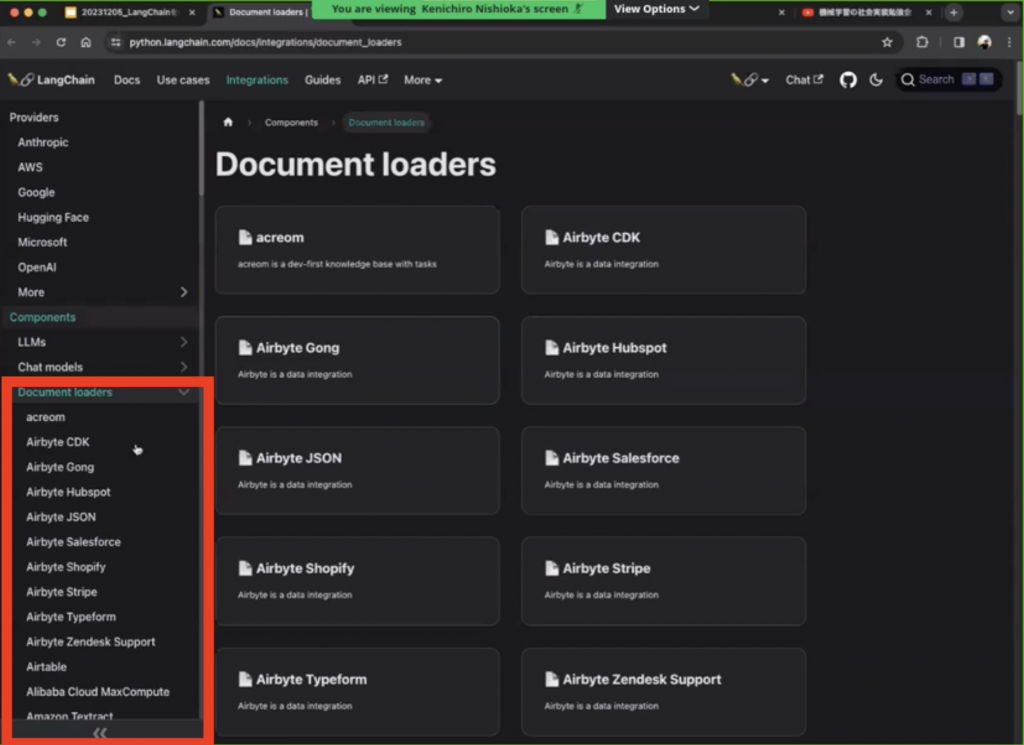
実際に赤色で示した部分をみていくとGmailだったり、DropboxやGithubなどもあったりします。
今回は「Arxiv Loader」と「Youtube Loader」というものを使ってお見せしていこうかと思います。
LangChainを使ったデータ参照について
ChatGPTなどの大規模言語モデルに質問をなげて、回答が帰った時に、なにを根拠にしているのか(どのデータを参照したか)というのをLang Chainをつかってトラッキングできるようにしていくというところをお見せしていきます。

まず、外部データソースを連携させる仕組みを作らないといけないのですが、そのためにRAG(Retrieval Augumented Generation)を構築します。
質問に関連した外部のリソースなどをChatGPTなどに連携し、回答の精度高めるような手法のこと
※補足
先月の11月15日にはRAGを使ったチャットBotについて解説しております。
どのように動いているのかも、この後お見せします。
また、入力された質問に対して、データを検索し、回答を生成するとった行程で、データ検索を行う際に、Vector Database を使ってセマンティック検索というものを行って、質問に対し、その解答に近い内容を引っ張ってきております。
また、Vector Databaseとは元のオブジェクトを数値型に変換し、特定の長さの数値にして埋め込んで保存しているデータベースのことです。
こうすることで、埋め込まれたベクトル同士の距離や近さを計算することが迅速に行え、同時に埋め込まれたベクトルに関連するメタ情報(たとえば、どの文書から生成されたか)を数値で保持することができます。
通常のリレーショナルデータベースがインデックスを使用してデータを高速に取得するのとは異なり、ベクトルデータベースはベクトル空間において特定のベクトルに近いベクトルを抽出するのが得意です。

社内のデータを連携するための2つのステップ
ステップ1:インデックスを作成
RAGを行うためには手元にあるデータを数値化とベクトル化にする必要があります。
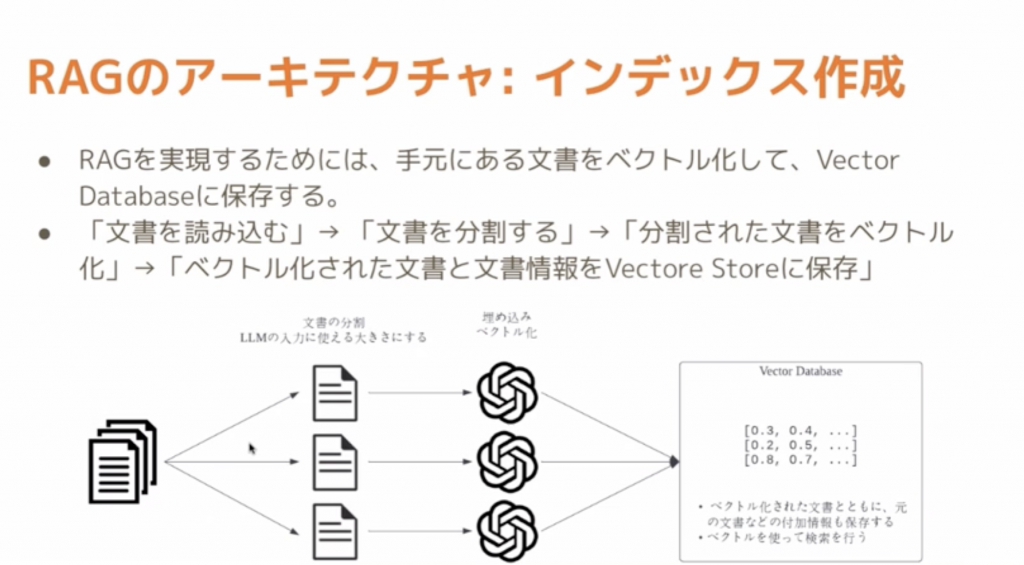
上の画像の「2項目目」にあたる部分がインデックス作成の流れになります。
どんなに長い文章に関しても細かく(ベクトル化できるぐらいに)分割していくことが必要になります。
ステップ2:LLMの大規模言語モデルのプロンプトの作成
質問例「社内研修はどうなっていますか」
このような質問文をベクトル化し、その解答に近いベクトルをVector databaseから探し、その近いベクトルから解答を生成するということをしていきます。

上で述べたステップ1とステップ2の行程をまるっと吸収してくれるのがLangChainとなります。今回のDocument roaderであったり、大規模言語モデルを取り巻く環境で必要な作業を簡単にしてくれます。
これのおかげで、ChatGPT単体では不可能であったことも可能にできたものもあります。最新のデータや既存のデータを組み合わせることで、精度の高い解答を生成することができるようになります。
ちなみに、LangChainを使わなくとも、自分でプロンプトを作成したり、自分でベクトルデータベースと連携させることで代替は可能です。ただ、LangChainでやると簡単に実装することができます。
それでは実践していきます。
実践:Arxiv Loader(アーカイブローダー)
※コード等も含め画像での記事となります。ご了承ください
今回扱うのはこちらのPDFになります。

これを、jupyter notebookでLangChainを使って読み込ませていきます。
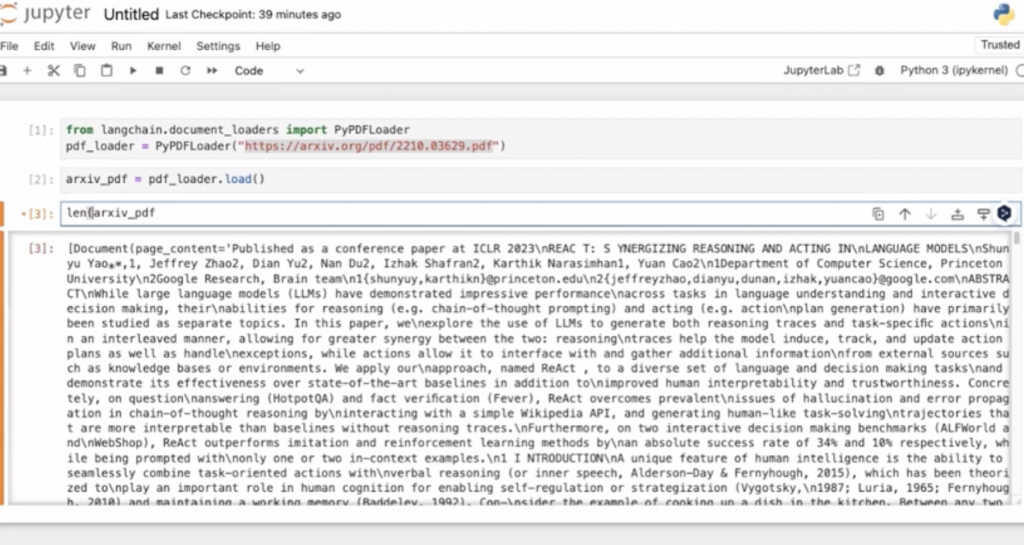
このように、リストの形でまとまっております。長さは33個の配列となってるのが確認できました。これはPDFが全部で33枚だったため、そのように構成されています。
また、下の画像のように最初の配列には「Document」というものが必ず入ってきます。これはPDFに関わらず、アーカイブローダーであったりYoutubeのトランスクリプションを読むローダーであろうが全てこれに落とされます。
実際に読み込まれた文書については「page_content」と入力すると、見ることができます。
・・・改行が変なところにあったりと、気になる点もいくつかあります。。。
また、Lang Chainを使う利点としてはサイトのURLなど、メタ情報を拾うことができます。(今回はPDFデータのため情報がすくないです。。。)

今度はアーカイブローダーで読み込んで実行してみたいと思います。
先ほどは33個あったドキュメントが1つになり、さらに中身は文字化けしてしまっているものも確認できました。このままだと、文章が長すぎたり、トークン数の制限を超えてしまったりする問題もあります。(処理に関しては後ほど)
また、今回のようにPyPDFではなく、アーカイブローダーの方を使う理由としては、先ほどみた「meta_data」が大量に入るという利点がございます。

これが後々の実装に役立ってきます。
実践:YouTube Loader
※こちらもコード等含め全て画像になります。ご了承ください。
早速実装してみます。こちらは西岡さんのYouTubeチャンネルになります。
ドキュメントを見てみますと、以下のような文章が保存されています。これはYouTubeの仕様にある、「文字起こし」の文章がそのまま入っております。

文字数をカウントすると約2万文字ございました。
では、トークン数がいくつなのか。こちらも見ていきたいと思います。トークン数はLangChainではなく、tictokenというものを使って見ていきます。
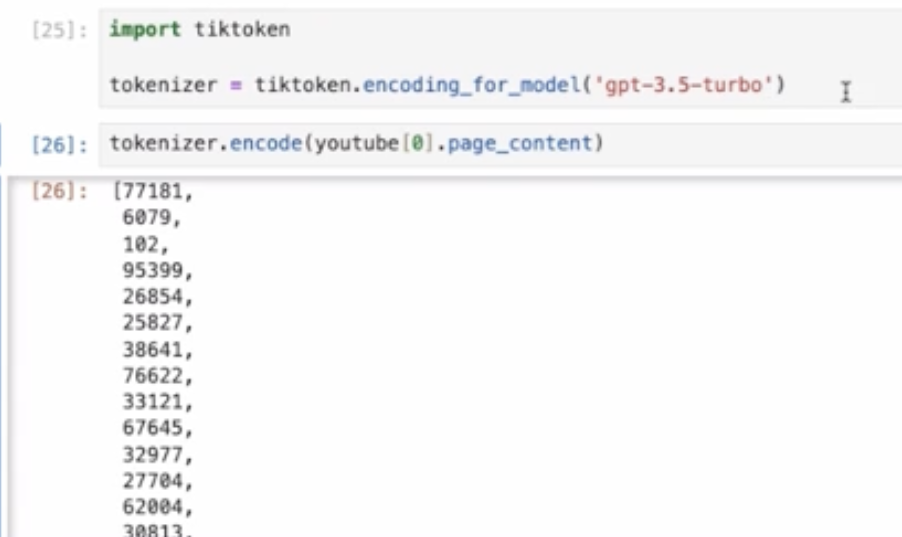
長さも2万ほどあり、これではChatGPTに投げるのはかなり難しそうです。

そこで、Lang Chainでは「split」というコマンドを使うことで2万ある長さのものを、6つに簡単に分けることができます。
下の画像で上の数(21099)と下の数(6)を見比べてください。
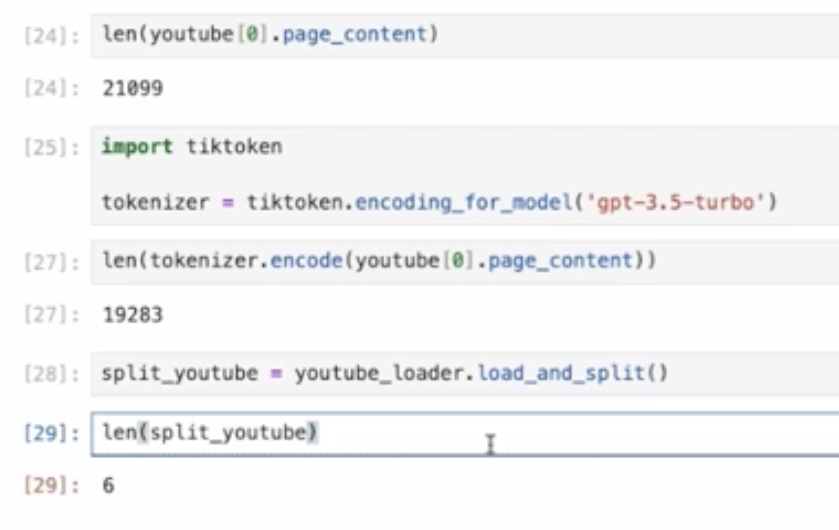
また、スプリットする際に、自分で法則を決めたいなど、こだわりが出てくると思います。そのような場合のために、いくつかのライブラリが用意されています。
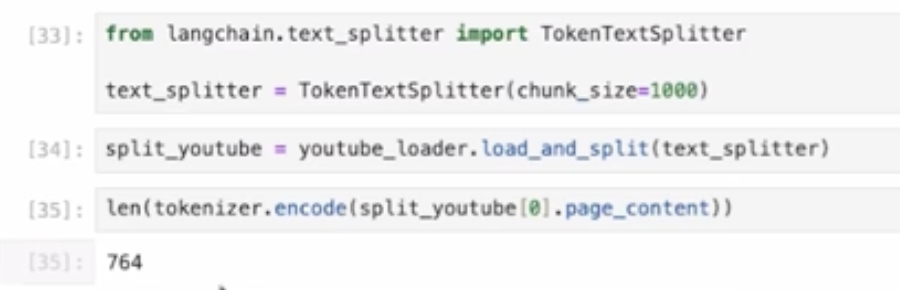
このTokenTextSpliterというのはトークンベースで分けるというものです。他にもスペースやタブでの区切りで分けるものもあります。ちなみに今回はトークン数が764となっています。
そして、このsplit_youtbeの長さを見てみると
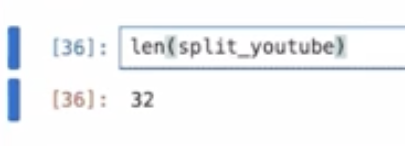
32となっていました。これはこのYouTubeの情報が32個の情報に分割されているということになります。これをVector baseに入れて、解答生成に連携していくというところをお見せしていきます。
実践(Vector baseとの連携)
この「load_dotenv」というのはOpenAIのエンべディングを使うための環境を整える必要があるため、読み込んであります。
また、プロンプトを見れる状態にするため、次のような設定もしておきます。

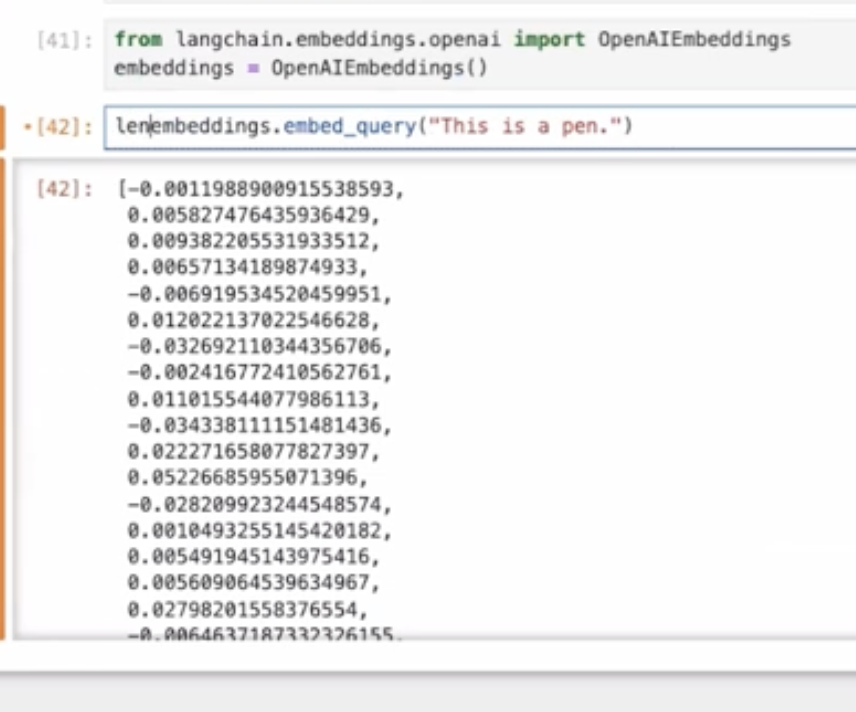
今回はChatGPTでなく、OpenAIのtextEmbeddingのAPIを使って行っていきます。試しに「This is a pen」という文書をベクトル化すると以下のような数値になります。
また、長さをとると、1536となっておりました。
この数値は単なる「pen」だろうが、なんだろうが変化しません。つまり、指定範囲のある枠組みに落とし込まれているということになります。これにより、近いベクトルを探す計算がしやすくなっているということになります。
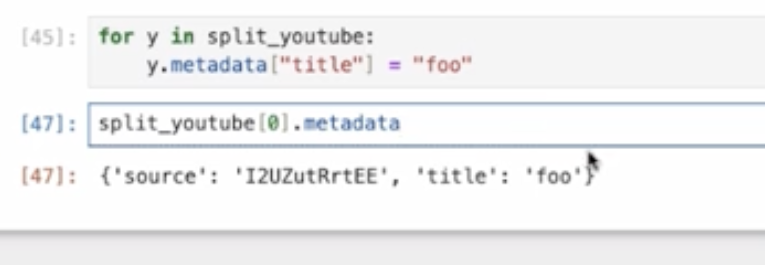
ここで、メタデータに「foo」というタイトルを入れてみます。これをする目的は「後から自分が入れたデータについてもみれますよ」という説明をするためになります。・・・あまり、metadataがないですね、、、
実際に何かを検索する時にはこのメタデータを良くして行くことが重要になってくると思っています。
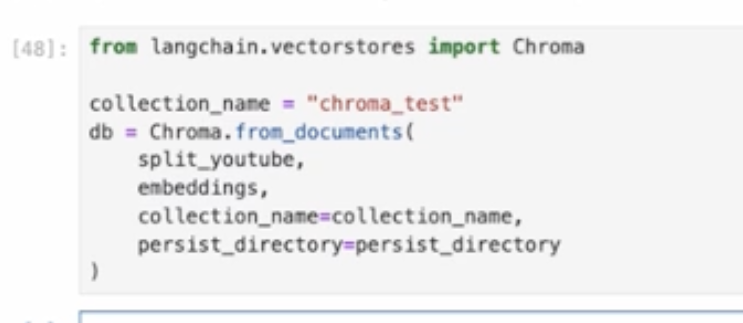
次にベクトルデータベースにデータをいれます。こんかいはCromaというデータベースに入れます。
Cromaはテキストエンべディングがしやすいデータベースとなっています。LangChainにおいてもよく使われています。
ただ、バックエンドだったり、インフラとなると他のデータベースを利用することもあります。
また、コードの詳細ですが「split_youtube」というものを読み込み、OpenAiのエンべディングをつかい、chroma_testというコレクションネームを読み込み、ローカルのディレクトリに保存するという流れになります。それでは実行
これで、ベクトルデータベースに入った状態になります。
次にベクトルデータベースの中から、情報を引っ張ってくることをします。それには「RetrievalQA」というものを使います。
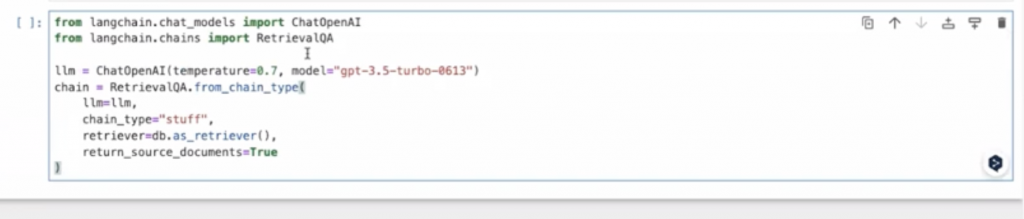
これで準備が整いました。それでは質問を投げたいと思います。

さて、この質問に対する答えを表示するためにどんな動きをしているかをみてみたいと思います。
画像、緑文字からはじまる1行目の「System」という行には「ユーザーの質問に答えてください。」そしてその下2行目には「わからない場合は無理に答えないでください。」とあります。これは頑張ってそれっぽい答えを作ってしまうことをしないでという抑制をしております。。

また、中央には4つのブロックに分かれて文章が並んでいます。これは今回の質問の解答に近いブロックを4つ引っ張り出してきたということになります。そして、この4つのブロックのしたには先ほど出した質問文があります。

それでは結果を見てみます。上の解答をまとめ、ChatGPTが答えを出してくれています。

この解答の根拠は何かというと、ドキュメントをみるとわかります。また、下にはmetadataについても書かれております。

以上が実装までの流れになります。
最後に
今回の実装についてはOpenAIのAPI単体では実現することができません。なぜなら、データはいれることができても管理することができないという点になります。つまり、データの管理の仕組みを自分で作らなければならないという問題があります。
そこでLangChainです。
このLangChainにある「RetrievalQA」というものをつかつことで「Source Document==True 」とすることでベクトルデータベースとかに入っている情報とかにも全部連携した状態で答えと関連したものというふうにつなげてくれます。この面倒くさい部分を LangChainがカバーしてくれていることがわかります。
質疑応答
Q1.データベースについて最近LLM専用のVector databaseが新たなデータベースとして盛り上がっていますが、従来のRDBの活用の幅は狭まるのでしょうか.
実際はそんなことはないと思います。RDBはRDBで利点はあるのでちょっと使い道が違いますというぐらいなので、RDBは従来通り使うと思います。それに、RDBに特化しているものというのもあります。例えば、もともと数値データであったりとか文章データじゃないみたいなもの(商品の値段など)とかは今後も残り続けるため、そのような場合はRDBが使われると思います。
しかし、もともとの質問文が曖昧だったり、検索したいものが曖昧など、そのようなときに、Vector databaseでは似たような空間にボンって突っ込んでくれるので検索がうまくいくっていうのがあります。
このように、RDBで検索した方がいいものというのは、RDBで検索しなければならないのですが、元々の質問文っていうのがちゃんとしてない場合もあります。ですので、今後もRDBと使い分けて行く必要があるかなと思います。
ちなみに、このような事態の場合もLangChainエージェントの機能を使うことで、質問文をChatGPTと連携し、RDBに問い合わせるということができたりもします。
Q2.ローカル環境下での検証方法について実際に会社PCのローカル環境にてLangChain&商用利用可能なLLMを用いていろいろ検証してみたいのですが、どのLLMを選定すればよいでしょうか。会社PCのスペックは一般的なノートパソコンになります。
実際はローカルのほうでそんなにCPUを食うことはないです。もちろんVector databaseが大きくなったらパフォーマンスとか出てくるのかなというのは思うんですけれども、LLMとかのAPI呼び出すであったりとかは文字を埋め込んだりとかそれぐらいの話なので、そんなに何か困るっていうことはないのかなというふうには思います。
また、検証方法とLLMを選定については、APIで呼び出せるものがいいと思います。ローカルにLLMを自分で構築するっていうのは、PCの負荷がスペックが必要になるので、通常やるのであれば、ChatGPTのAPIでやったりとか、あとはParmのAPIを呼び出すのをお勧めします。
Q3.会社でMicrosoftOffice特にExcelを対応しているのですが、Excelファイルを読み込むことは可能でしょうか。もし読み込むことができる場合、事前にExcelファイルに対してデータクレンジングを行うこととなると思いますが何か着意すべき事項とありましたら教えてください。
Document loader の方にExcelがあります。Microsoft Excelでそれで読み込んでいただければUnstructured Excel Loaderというふうになります。実際に読み込んでうまく読めるかどうかっていうのは、実行しながら調整していただくのがいいのかなともいます。もちろんぐちゃぐちゃなExcelデータだと綺麗なデータにはならないとと思います。
Excel loaderを私もまだ使ったことがないのですけど、想像するに、シートごとにパーって読んでくる機能になるかと思います。。
Q4.Vector databaseへドキュメントを分割して格納する場合、分割の流度はどのような基準で設計するのが良いでしょうか。
重要なこととしては、検索した結果というものをプロンプトに埋め込む必要があります。先ほど質問文をなげ、結果がでるまでの内部の画像(結果出力が緑の文字で出てきているものです。)をお見せしたかと思います。デフォルトではプロンプトの数が4つになっておりましたが、こちらも1つにするのであれば、プラスして与えたいコンテクストっていうものをどのくらいの長さで入れるか、これに依存してきます。なので、やりたいことと、その検索結果というか、プロンプトに与えた文章の長さ、あとはどのモデルを使うかによって文章の長さというのが変わってくるようになります。
Q5.OpenAIのRetrieval機能も内部的に文章をベクトル化してVector Storeに入れてるんでしょうか。今後ラグをしたいときにLangChainを使うかOpenAIのアシスタンスAPIを使うかプローズコンズが分かっていないです。
OpenAIのRetrieval機能っていうものがどういうもので使ってはいないので、内部的にVector databaseを持っているかどうかというところです。もし、保存できる機能があるのであればVector databaseを内部に持っていて、オープンAIのエンベディングっていうものはモデルごとにあるので、それを使ってエンベディングして入れてるかと思います。詳細なアーキテクチャは今のところ私のところに情報はないです。
どちらかというと私は外部リソースでVector databaseを持っているので、OpenAIの中でVector databaseがどんなものなおかは理解していないんですけど、おそらくベクトル化してるんだと思います。
Q6.RAGをしたいときに、LangChainを使うかOpenAIのアシスタンスAPIのどちらを使いますか。プロズコンズがは分かっています。
LangChainに関しては、いい感じのプロンプトを作ったりとか、管理であったりとか、あとは先ほどお見せしたようにレスポンス元のVector databaseに入っているような情報を簡単に呼び出せる仕組みが用意されているのが便利なところです。
LangChainっていうのは、やっぱり1個の検索であったりとか、そういうものに対して、特にドキュメントに、ドキュメントクラスにまとめることとか、ドキュメントクラスからこういうふうに情報を取ってくるでこととか、そのような決まったフレームワークを用意してあげるところが使いやすいところになります。
細かい部分は実際のOpenAIのAPIを読んでるのと変わんないんですけれども、そこに一個かませることによって実装が楽になってるっていうようなイメージですね。
分かりかねる部分が多々あるのですけど、PythonでWebサーバーを作る場合を例にすると、Django使いましょうとかFastAPI使いましょうとかちょっとラップされてるものを使いましょうとかそういうふうなイメージです。「ちょっと便利な」「型化する」「抽象化する」それによって実装を簡単にしているという感じです。
簡単なものでも、LangChainってそんなに使うのが難しくない。むしろ、めちゃくちゃ簡単なので、テンプレート変えたいですとか、プロンプトのテンプレート変えたいですみたいな話で、それを調べるのがちょっと大変なのですが、使うこと自体は簡単なので、1回使ってみるのをおすすめします。
Q7.LangChainエージェントのツールを使用して、Googleサーチを行い、その結果から特定のURLを取得しそれを表示させることは可能ですか?
何を検索するか、サブAPIの呼び出すか何かにもよりますが、それは可能です。
LangChainエージェントはツールとして、いろいろなものを渡すのですけど、自分の欲しいアウトプットとかをちゃんとツールに持たせて検索したりすれば何でもできます。そのツールに関してはもちろん用意されてるサブAPIとかいろいろあったりするんです。自分が好きなように実装してそれをプログラム上でやり取りするってことは何でもできますという感じです。
Q8.RDBやデータウェアハウスに蓄積されているデータを参照してLLMに回答を生成してもらいたい場合はRDBVector databaseにベクトル形式でデータを保存するようなアーキテクチャになりますか。
文書データだったらそうなるんですけれども文書データじゃなければ必ずしてもVector Storeにする必要はありません。
どうするかというと、LangChainのエージェントや、OpenAIのファンクションコーリングでも何でもいいんですけど、「RDBで検索する場合には、こういうインプットをください」という話できちんとプロンプトの中に埋め込んであげて、その返ってきた結果を元に、RDBの検索を加える形になります。
一番わかりやすいのは商品名とかを使って検索する場合、別に商品の値段とかを引っ張ってくる場合とかはRDBのままChatGBTとやり取りして検索するということが自然で無駄がないと思います。Vector databaseにする必要性がないということです。
今回は以上です。最後までお読みいただきありがとうございました。

