
公開日:2019/9/30
更新日:2019/9/30
キーワード:Python 配列 リスト
文字数:7200(読み終わるまでおよそ12分)
この記事でわかること
- Pythonでのリストの特徴
- Pythonでのリストの操作方法
はじめに
プログラミングの世界では、「配列」という言葉をよく聞きます。配列とは、同じ型の要素を一列に並べたデータ型のことです。
Pythonでは配列いう言葉は使わず、配列のことを「リスト」と呼ぶのが一般的です。今回は、リストの扱い方を見ていきます。
1. Pythonでのリストの特徴

Pythonでは、リストが他の言語で言う配列の役割を担っていますが、Pythonのリストは、他の言語の配列と以下の違いがあります。
- リスト宣言時に、型を指定する必要がない
- 構成する各要素の型が違っていてもよい
Pythonにおけるリストとは、[ ]の中にカンマで区切られた複数の要素で構成されたオブジェクトです。
リストの大きな利点は、一度に多くのデータをまとめて扱える、という点があげられます。既存のメソッドを使って、要素の追加や削除、検索やカウントなどといった、色々な操作を行うことができ、データ解析においては重要なオブジェクトの一つです。
2. リストの操作

では、様々なリストの操作方法を見ていきましょう。
1) リストを作る
リストを作る方法はいくつかありますが、最も簡単な方法は、[ ]の中に要素をカンマで区切って入れていく方法です。
リストには、どのような型の要素でも入れることができます。
| [ 要素1, 要素2, 要素3, … ] |
具体的な例を見てみましょう(例文1-1)。
<例文1-1>
num_list = [5, 7, 2, 9, 100]
print(num_list)
country_list = ["Japan", "US", "UK", "China"]
print(country_list)
mix_list = [5, "Japan", 7.5, "US"] #要素の型は混在してもよい
print(mix_list)[5, 7, 2, 9, 100]
['Japan', 'US', 'UK', 'China']
[5, 'Japan', 7.5, 'US']リストは、print文で表示させることができます。リストの各要素の型は違っていても、問題ないことが分かります。
空のリストを明示的に作りたいあるいは、作成したリストを初期化したいときは、[ ] の中身を空で宣言するとリストが初期化され、空のリストを作ることができます(例文1-2)。
<例文1-2>
new_list = []
print(new_list)[]2) リストの要素の参照方法
リストの操作方法を見ていく前に、リストに入っている要素を参照する方法を先に見ておきます。リストの要素は、インデックス番号で管理されています。インデックス番号は先頭から、0、1、2、3・・・の順に数えます。
一方、後ろから数えるときは逆順で-1、-2、-3・・・の順に数えます。
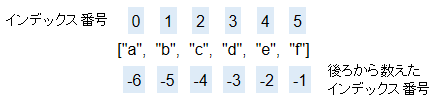
具体的な参照方法を例文2-1に示します。
<例文2-1>
country_list = ["Japan", "US", "UK", "China"]
print(country_list[0])
print(country_list[2])
print(country_list[-2])Japan
UK
UKリストの要素を順番に取り出すには、for文を使うと簡単です(例文2-2)。
<例文2-2>
country_list = ["Japan", "US", "UK", "China"]
for coun in country_list:
print("その国は、" + coun + "です。")その国は、Japanです。
その国は、USです。
その国は、UKです。
その国は、Chinaです。リストの要素が数値の場合、要素を取り出して文字列と組み合わせて表示しようとすると、型が異なるためエラーとなります(例文2-3)。
<例文2-3>
number = [22, 64, 95, 98, 5]
for num in number:
print("その値は、" + num + "です。")TypeError Traceback (most recent call last)
<ipython-input-11-190cee561adb> in <module>()
3 for num in number:
4
----> 5 print("その値は、" + num + "です。")
TypeError: must be str, not int数値の要素を取り出して、文字列と組み合わせて表示したい場合は、formatメソッドを用いる必要があります(例文2-4)。
<例文2-4>
number = [22, 64, 95, 98, 5]
for num in number:
n = "その値は、{} です。"
hyoji = n.format(num)
print(hyoji)その値は、22 です。
その値は、64 です。
その値は、95 です。
その値は、98 です。
その値は、5 です。formatメソッドの代わりにfプレフィックスを用いると、シンプルに書くことができます(例文2-5)。
<例文2-5>
number = [22, 64, 95, 98, 5]
for num in number:
print(f"その値は、{num} です。")その値は、22 です。
その値は、64 です。
その値は、95 です。
その値は、98 です。
その値は、5 です。3) リストへの要素の追加・挿入
既存のリストに要素を追加したり、途中に挿入するには、appendメソッド、insertメソッドを使います。
リストの末尾に要素を追加するには、appendメソッドを使います。
| append(値) |
appendメソッドはリストオブジェクトのメソッドなので、要素が何もないリストに要素を追加したい場合は、最初に空のリストを作っておく必要があります。
appendメソッドを使うことで、リストの末尾に値を追加できます(例文3-1)。
<例文3-1>
list = [] #からのリストを作る
list.append(1)
list.append(10)
print(list)
list.append(100)
print(list)[1, 10]
[1, 10, 100]リストの途中に要素を挿入するには、insertメソッドを使います。第1引数で挿入位置を指定し、第2引数で挿入する要素を指定します(例文2-2)。
| insert(挿入位置, 値) |
<例文3-2>
list = ["A", "B", "C", "D", "E"]
list.insert(4, "fff")
print(list)['A', 'B', 'C', 'D', 'fff', 'E']インデックス番号4の位置に、”fff”の文字列を挿入しています。インデックス番号4の位置には”E”があるので、”E”の前に”fff”が挿入されます。
リスト同士を連結したいときは、文字列を連結するように+演算子を使います(例文3-3)。
<例文3-3>
country1 = ["Japan", "US", "China"]
country2 = ["UK", "France"]
country = country1 + country2
print(country)['Japan', 'US', 'China', 'UK', 'France']リスト同士の連結には、extendメソッドを使うこともできます(例文3-4)。
<例文3-4>
country1 = ["Japan", "US", "China"]
country2 = ["UK", "France"]
country1.extend(country2)
print(country1)['Japan', 'US', 'China', 'UK', 'France']4) リストの要素の削除
リストから要素を削除するには、目的に応じて、popメソッド、removeメソッド、del文を使うので、それぞれの使い方を見ていきましょう。
popメソッドは、リストの末尾を削除し、削除した値を返すメソッドです。例文4-1のcountry_listには、最初は4か国が入っています。次に、popメソッドを実行してcountryに代入します。
countryの値を見ると、county_listの末尾の”China”が入っており、元のcounty_listを見ると、取り出した”China”が削除されていることが分かります。
<例文4-1>
country_list = ["Japan", "US", "UK", "China"]
country = country_list.pop()
print(country)
print(country_list)China
['Japan', 'US', 'UK']引数の無いpopメソッドは末尾の要素を取り出しますが、引数に位置を指定することもできます。
| pop(抜き取る位置) |
pop(0)で、最初の要素を取り出します(例文4-2)。
<例文4-2>
country_list = ["Japan", "US", "UK", "China"]
country = country_list.pop(0)
print(country)
print(country_list)Japan
['US', 'UK', 'China']popメソッドは、要素の位置を指定するメソッドでしたが、リストの要素の並び順ではなく、削除したい特定の値が分かっている場合があります。そのときは、removeメソッドを用います(例文4-3)。
<例文4-3>
country_list = ["Japan", "US", "UK", "China"]
country_list.remove("UK")
print(country_list)['Japan', 'US', 'China']削除したい値が複数ある場合は、最初に見つけた値のみが削除されるので、注意が必要です(例文4-4)。
<例文4-4>
country_list = ["Japan", "US", "UK", "Japan", "China"]
country_list.remove("Japan")
print(country_list)['US', 'UK', 'Japan', 'China']リストに含まれる削除したい値をすべて削除するのは、繰り返し処理が必要となります(例文4-5)。
<例文4-5>
country_list = ["Japan", "US", "UK", "Japan", "China"]
while "Japan" in country_list:
country_list.remove("Japan")
print(country_list)['US', 'UK', 'China']del文を使って、リストの位置を指定して要素を削除することもできます(例文4-6)。
<例文4-6>
country_list = ["Japan", "US", "UK", "China"]
del country_list[1]
print(country_list)['Japan', 'UK', 'China']del文はオブジェクトそのものを削除できるので、作成したリストや変数を削除するのに使うことができます(例文4-7)。
<例文4-7>
country_list = ["Japan", "US", "UK", "China"]
del country_list
print(country_list)NameError Traceback (most recent call last)
<ipython-input-8-17059f3538bc> in <module>()
3 del country_list
4
----> 5 print(country_list)
NameError: name 'country_list' is not defined一度作成したcountry_listが、del文で削除されていることが分かります。
5) リストに含まれる要素の検索
リストに含まれる要素を検索するには、目的によっていくつかの方法があります。
要素が含まれるかを知りたい場合は、in演算子を使います。値が含まれていればTrue、含まれていなければFalseになります(例文5-1)。
<例文5-1>
country_list = ["Japan", "US", "UK", "China"]
a = "US" in country_list
b = "Italy" in country_list
print(a)
print(b)True
False要素が見つかった位置を知りたい場合は、indexメソッドを使います(例文5-2)。
<例文5-2>
country_list = ["Japan", "US", "UK", "China"]
country_list.index("UK")2要素が見つからなかった場合は、エラーとなります(例文5-3)。
<例文5-3>
country_list = ["Japan", "US", "UK", "China"]
country_list.index("Italy")ValueError Traceback (most recent call last)
<ipython-input-7-eb41f100588f> in <module>()
1 country_list = ["Japan", "US", "UK", "China"]
2
----> 3 country_list.index("Italy")
ValueError: 'Italy' is not in list見つかった要素の個数を知りたい場合は、countメソッドを使います。指定の要素が見つからなかった場合は、0が返ります。
3を指定して検索した場合、23、36など、一部に指定の値が含まれている要素は、対象とはなりません(例文5-4)。
<例文5-4>
number = [2, 3, 13, 25, 3, 36, 57, 3]
number.count(3)36) リストの要素の並び替え
リストの要素をソートするには、sortメソッドを使います。デフォルトは昇順に並び替えるので、降順に並び替えたいときは、sort(reverse = True)と引数を指定します(例文6-1)。
<例文6-1>
number = [22, 64, 95, 98, 5, 66, 83, 86, 98, 1]
a = number.sort()
print(number)
b = number.sort(reverse = True)
print(number)[1, 5, 22, 64, 66, 83, 86, 95, 98, 98]
[98, 98, 95, 86, 83, 66, 64, 22, 5, 1]sortメソッドは元のリストの要素を直接並び替えますが、元の並び順は維持したままにしたいときは、sorted関数を使います(例文6-2)。
sortedは関数なので書き方に気を付けましょう。なお、逆順で並び替えたい場合は、sortメソッドと同様に引数で指定します。
<例文6-2>
number = [22, 64, 95, 98, 5, 66, 83, 86, 98, 1]
a = sorted(number)
b = sorted(number, reverse = True)
print(a)
print(b)
print(number)[1, 5, 22, 64, 66, 83, 86, 95, 98, 98]
[98, 98, 95, 86, 83, 66, 64, 22, 5, 1]
[22, 64, 95, 98, 5, 66, 83, 86, 98, 1]要素の大きさでソートするのではなく、単純に要素の順番を逆にしたいときは、reverseメソッドを使います。sortメソッドと同じく、元のリストの要素を直接並び替えるので、注意してください(例文6-3)。
<例文6-3>
number = [22, 64, 95, 98, 5, 66, 83, 86, 98, 1]
number.reverse()
print(number)[1, 98, 86, 83, 66, 5, 98, 95, 64, 22]元のリストを維持したまま、要素の順番を逆にしたリストを作りたい場合は、元のリストをスライスすることで作成できます(例文6-4)。
<例文6-4>
number = [22, 64, 95, 98, 5, 66, 83, 86, 98, 1]
a = number[::-1] #スライスを使って逆順のリストを作成
print(a) #並び替えたリストを表示
print(number) #元のリストを表示[1, 98, 86, 83, 66, 5, 98, 95, 64, 22]
[22, 64, 95, 98, 5, 66, 83, 86, 98, 1]元のリストであるnumberが、そのまま維持されていることが分かります。
7) NumPy配列の活用
Numpyライブラリの配列(NumPy配列)は、これまで述べてきたPython標準のリストよりも効率的に、多次元配列を扱うことができます。それにより、高速で行列計算ができるようになり、行列演算が重視される機械学習において活用されています。
Pythonで機械学習を行う際によく用いられるscikit-learnは、NumPy配列で入力を受け取るため、使用するデータはNumPy配列に変換する必要があります。
本稿では、NumPy配列について詳しく述べませんが、Pythonで機械学習を行いたい方は、NumPy配列もしっかり勉強しておいてください。
3. おわりに
今回は、複数の値をまとめて扱いたいときに用いる、「リスト」を中心に述べてきました。
リストは、変数や繰り返し処理と同様に、最も基本的な処理ですので、リストの使い方はしっかりと理解しておいてください。
機械学習に取り組みたい方は、NumPy配列もしっかり学習しておきましょう。
4. 参考サイト
入門者必見!Pythonのリスト(配列)を使いこなすための5つのステップ
https://www.sejuku.net/blog/32681
python 配列基礎はこれで完璧!便利なメソッド多数紹介
https://udemy.benesse.co.jp/development/web/python-list.html
listの使い方とメソッドまとめ
https://www.sejuku.net/blog/23633
