はじめに
今回は、機械学習のアルゴリズムの一つである「決定木分析」を紹介します。
決定木分析とは、分類または回帰を行いたいときに広く用いられている分析手法で、一連の質問に基づいてYes/Noで判断して構成された、階層的な樹木状のモデルを作成する手法です。
機械学習のアルゴリズムでよく聞く「ランダムフォレスト」は、簡単に言うと決定木をたくさん集めたものですので、ランダムフォレストの仕組みを理解するためには、その基本となる決定木分析を見ておく必要があります。
決定木分析の詳細
1) 決定木分析とは
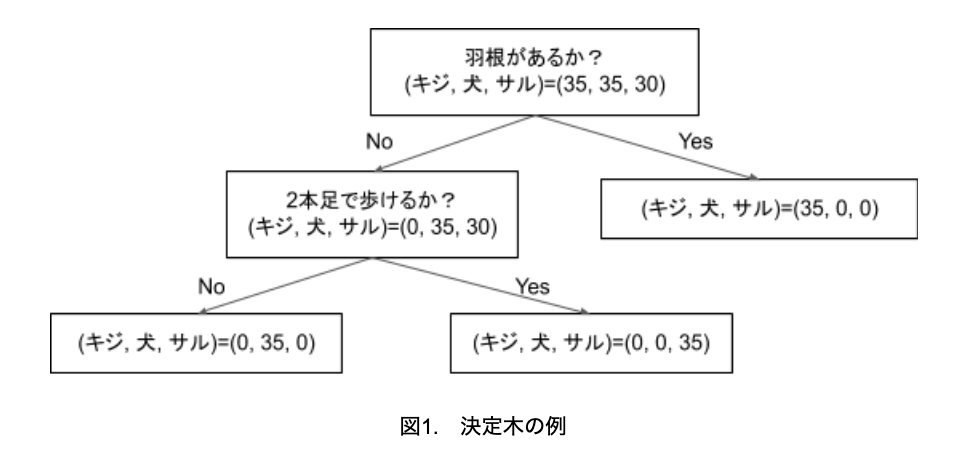
決定木分析は教師あり学習に使われるアルゴリズムの一つで、決定木分析のイメージを図にすると、図1のようになります。これは、キジ、犬、サルを分類するモデルの例です。
上述したように樹木状のモデルで、各枝では特徴量を利用してデータを分類します。そして、最後の葉になる部分で、分類結果が決まります。
図1の場合、全体のサンプル数は100個で、キジ、犬、サルのサンプル数はそれぞれ35、35、30です。まず、羽根の有無という特徴量で、キジとそれ以外に分類できます。そして、2本足で歩けるかという特徴量で、犬とサルに分類できます。
2本足で歩けるかなど、特徴量の箱をノードと言い、最終結果の箱を終端ノードと言います。終端にノードは葉、葉ノードなどとも呼ばれます。
図1の場合、最終的にはキジ、犬、サルのいずれかにきれいに分類できていますが、サンプルの中に2本足で歩ける器用な犬など、いわゆる外れ値が入っていると正しく分類できず、精度が低下することになります。
かと言って、そのような外れ値に合わせようと細かく分けようとすると、モデルが複雑になって過学習に陥ってしまうので、バランスを取る必要があります。
さて図1では、特徴量はカテゴリのみでしたが、数値の場合でも解析することができます。その場合、しきい値を設けて、そのしきい値より大きいか小さいかで分類することになります。(例えば、「重量」という特徴量がある場合、1kg以上かどうか)
また、分類問題だけでなく、回帰問題にも適用することができる、汎用性の高い分析方法です。
2) 決定木分析のポイント
決定木分析でポイントとなるのは、
① 複数ある特徴量のうち、どの特徴量をどのくらい使うか
② どこまで奥深く木を伸ばすか
の2点となります。
色々な特徴量を使ってとことんまで奥深く木を伸ばせば、完璧に分類できるのではと思われるかもしれません。
しかし、もしそのようにすれば、モデルが複雑になりすぎてしまいます。その結果、学習用のデータに対しては予測精度は非常に高くなりますが、モデル作成に使っていない検証用データに対しては、精度が上がらない「過学習」の状態になり、汎化性能の低いモデルとなってしまいます。
そこで、汎化性能を確保するためには、適度な深さで分割を止める必要があります。
どの特徴量でデータを分割するかは、情報利得と呼ばれる指標が最大となるように決められます。ここでは、情報利得の詳細な説明は省略しますが、簡単に言うと、きれいに分類できる度合いです。
図1の例で、重量という特徴量もあったとしましょう。もし、重量でキジ、犬、サルを分類しようとしても、きれいに分類できないであろうことが想像できると思います。これは、重量で分類しても情報利得が小さいことを意味しており、分類に用いるのは不適切と判断します。
3) 決定木分析の具体例
それでは、Pythonのscikit-learnで用意されているcancerデータを使って、実際に決定木分析を行ってみましょう。
cancerデータとは、乳がんの検査で採取した細胞のデジタル画像から、30の特徴量を抽出し、それぞれのサンプルに対して、良性腫瘍か悪性腫瘍の診断結果が付けられている分類データです。
まずは、木の深さを指定しないで分析してみます。
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
#データの読み込み
cancer = load_breast_cancer()
#学習用データとテスト用データに分割
X_train, X_test, Y_train, Y_test = train_test_split(
cancer.data, cancer.target, stratify=cancer.target, random_state=10)
#決定木分析
tree = DecisionTreeClassifier(random_state=1)
tree.fit(X_train, Y_train)
#結果
print("学習用データの精度:{:.3f}".format(tree.score(X_train, Y_train)))
print("テスト用データの精度:{:.3f}".format(tree.score(X_test, Y_test)))学習用データの精度:1.000
テスト用データの精度:0.944
木の深さを制限しなかったため、学習用データの精度は100%でした。これは、終端ノードが純粋ですべての学習用データを完全に分類できていることを意味します。
テスト用データに対しては、精度は94.4%とまずまずでしたが、木の深さに制限を与え、汎化性能を高めることで、精度の向上が期待できます。
そこで、最大の深さを5に制限して、再分析してみましょう。
tree = DecisionTreeClassifier(max_depth=5, random_state=1)
tree.fit(X_train, Y_train)
print("学習用データの精度:{:.3f}".format(tree.score(X_train, Y_train)))
print("テスト用データの精度:{:.3f}".format(tree.score(X_test, Y_test)))学習用データの精度:0.993
テスト用データの精度:0.951
学習用データの精度は99.3%と低下しましたが、テスト用データの精度は95.1%と上昇していることが分かります。
このように、未知のデータに対する精度を挙げるためには、木の深さを制限する必要があるのです。
4) 決定木の見える化
決定木分析の大きなメリットの一つは、どのように分類したのか、途中のプロセスが見えることです。分析のプロセスを見える化することで、次のアクションにつなげやすくなります。
では、cancerデータの決定木分析結果(最大深さ5の方)を見える化してみましょう。
from sklearn.tree import export_graphviz
import graphviz
tree_data=export_graphviz(tree, out_file=None, class_names=["悪性", "良性"],
feature_names=cancer.feature_names, impurity=False, filled=True)
graphviz.Source(tree_data)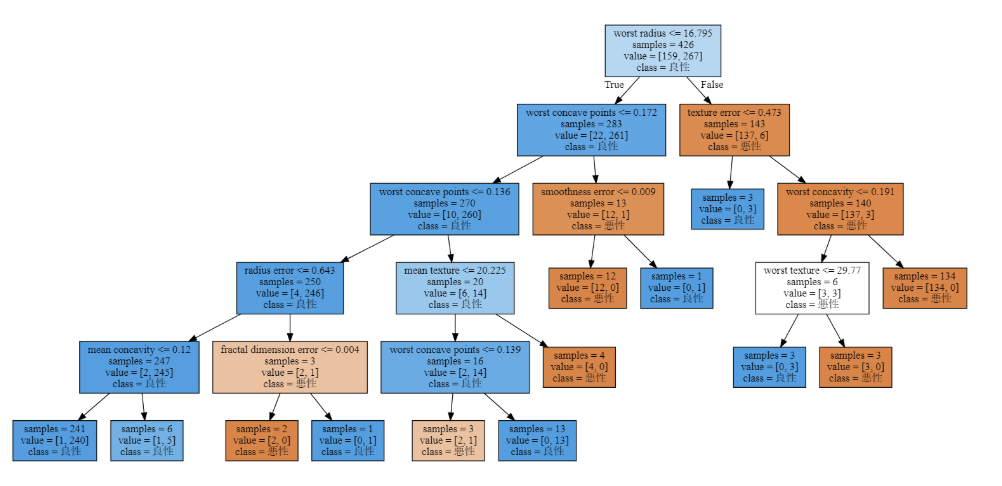
木の深さの最大を5に制限しているため、5層で終わっていることが分かります。字が小さいので、2層目までを拡大したものを図2に示します。
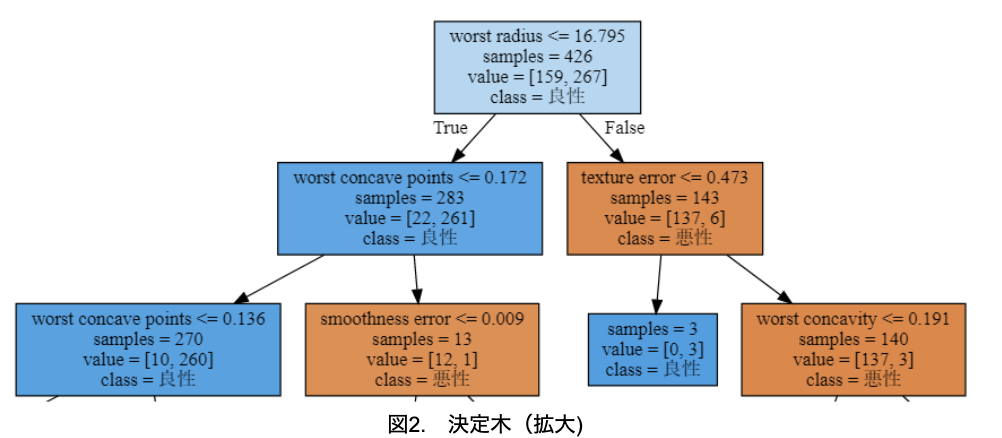
学習用データは426あり、悪性が159、良性は267と良性が多いことが分かります。初めにworst radiusが16.795以下かどうかを判定します。16.795以下のデータは283個で良性が優勢、16.795より大きいデータは143個で悪性が優勢と分かります。以下、同じように読み取ることが可能です。箱の色と濃さは、どちらのクラスがどのくらい優勢かを示しています。
そして、完全に分類できた、または、木の深さが5になった時点で、終わりとなります。図2の最下段の右から2つ目のノードは、良性のみに分類できており、終端ノードであることを示します。
このように、どのような判断基準で分類したのかが明確に分かるので、決定木分析は分析結果を考察しやすいのです。
5) 特徴量の重要性
決定木分析は、そのプロセスを見える化できるのが大きな特徴です。しかし、それでも決定木全体を細かく見るのは大変なので、特徴量の重要度がよく使われます。これは、決定木が判断を行うにあたり、個々の特徴量がどのくらい重要かを割合で示したものです(図3)。
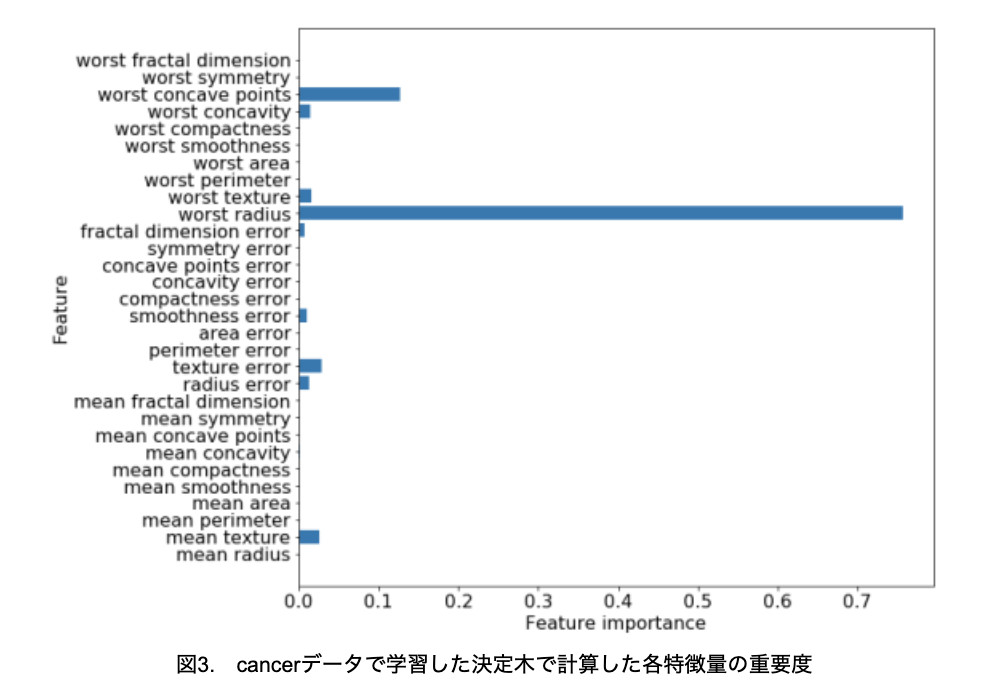
図2ではどの特徴量が重要か分かりにくいですが、重要度を計算することでworst radiusが最も重要な特徴量であることが、一目でわかります。
このように、特徴量の重要度を算出することで、決定木分析の結果をさらに解析しやすくすることができます。
6) 決定木のメリットとデメリット
決定木のメリットとデメリットとして、以下が挙げられます。
①メリット
・可視化や解釈が容易にできる
図2や図3のように、解析結果を見える化できるので、結果の解釈が容易となります。
・標準化などデータの前処理がいらない
サポートベクターマシンやニューラルネットワークのように、データを標準化する必要がありません。データをそのまま解析しても、標準化して解析しても、解析結果は同じです。
・データが非線形の場合でも適用できる
非線形のデータであっても、適切に特徴量やしきい値を決めてくれます。
②デメリット
・外れ値の影響を受けやすい
外れ値が多いと、外れ値に引っ張られて分類する境界が大きく変わってしまう可能性があります。
おわりに
今回は決定木分析を見てきました。決定木分析は、途中のプロセスが見えるので、結果の解釈がしやすいメリットがあります。
その分、複雑なデータセットに対しては予測精度が上がりにくい傾向がありますが、その弱点をカバーするため、ランダムフォレストが使われます。ランダムフォレストの基本は決定木分析なので、ランダムフォレストを学ぶ際は、まず決定木分析を理解してください。
参考サイト
決定木分析についてざっくりまとめ_理論編
【機械学習】決定木
piponではエンジニアの皆様に業務委託や副業でAI・データサイエンスの案件をご紹介しています!
piponの案件にご興味がある方は以下のフォームにご登録ください。案件をご案内します。 https://share.hsforms.com/1qk0uPA_lSu-nUFIvih16CQegfgt