
先日行った勉強会で「CodeInter preter」の使い方について解説いたしました。
また、その前にも「Open Interpreter」についても解説いたしました。そのときのイベントレポートはこちらです!
Open Interpreter はローカル環境で動かしていくため、PythonのインストールだったりAPIの使用料金がかかってきます。そのため、非エンジニアの方にとっては使用するのにハードルが高いのではと感じております。
一方、Code InterpreterはChatGPTの画面上で操作していくので、どのような方にとっても使いやすいと思っております。
今回はそのCode Interpreterを中心に解説していきます!
Code Interpreterの概要
「どんなことができるか」の前に、Code Interpreterの概要についてまとめておこうと思います。すでにご存知の方は読み飛ばしていただいて構いません。
CodeInterpreterとは
(今現在はAdvanced Data Analysisと)
ChatGPTの有償サービス(月額20ドル)「ChatGPT Plus」の機能です。Code Interpreterとは自然言語で指示を出すと、プログラムに変換して実行してくれるツールです。つまり、プロンプトでコードの生成だけでなく、実行までしてくれます!
実際にCode Interpreterの実行画面を説明します。
例えば、以下のようにスプレッドシートと一緒に「どんなデータか読み取って説明して」と言うと
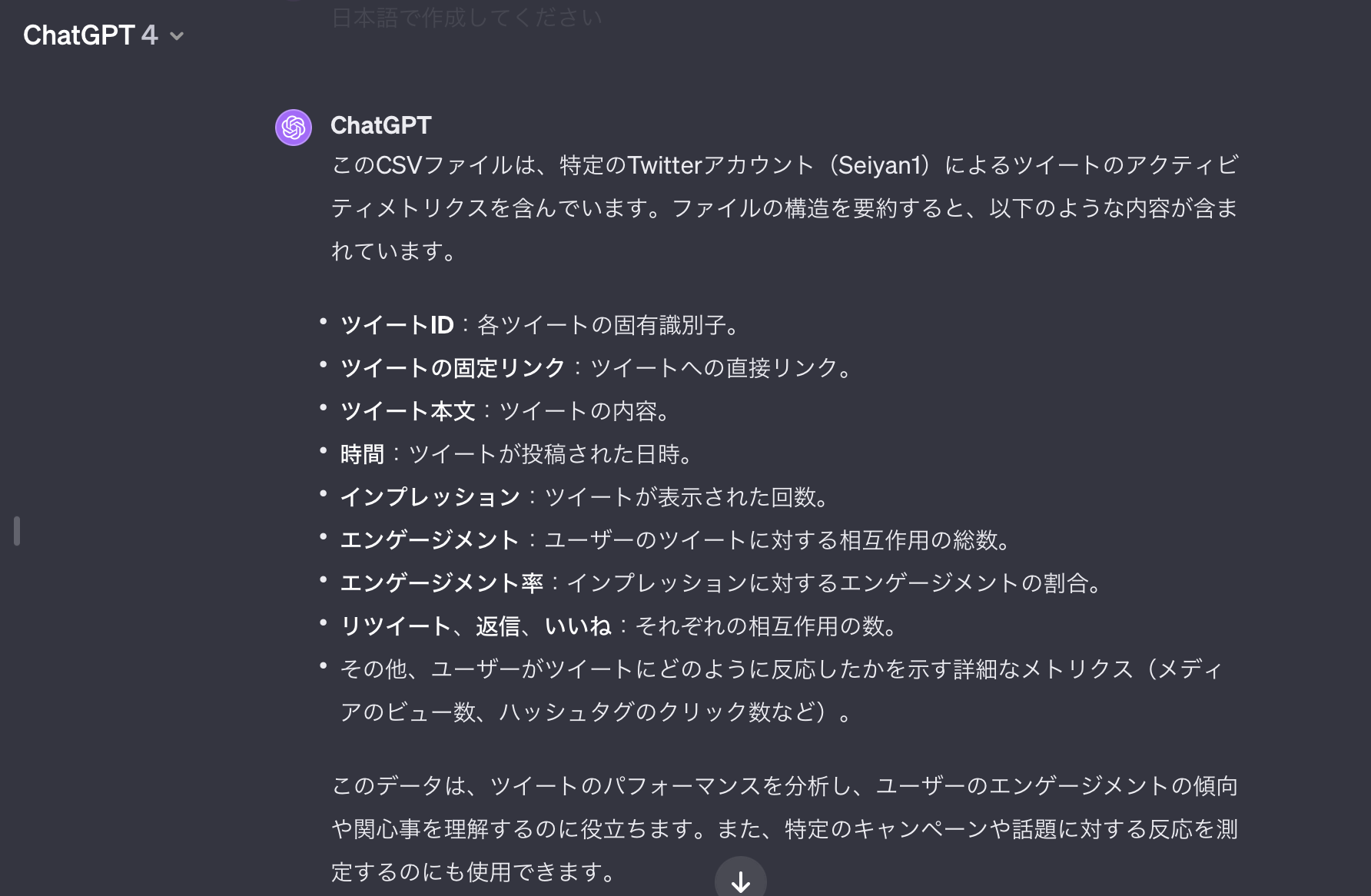
以下のように概要を説明してくれます。
そして、Code Interpreterは、プログラミングの環境がなくてもChatGPTの画面の中で「Python」を実行することもできます。
今までChatGPTはコードは作ってくれるけど、実行はしてくれませんでした。しかし、このCode Intepreterを使うことで、コードを生成し、さらに実行した結果、その解釈までしてくれます。
※データをCode InterpreterはChatGPTのWeb上にデータ等をアップロードしながら作業を行います。もし、これらに抵抗がある場合はOpen Interpreterを用いることで、ローカルで動かすことができます。ぜひ、上の記事を参照してください!
Code Interpreterの様々な使い方
今回紹介するのは以下の3つになります。
- データ解析
Twitterのデータを解析 - 資料作成
パワポの構成の作成 - 予測モデルの作成
タイタニックのデータから生存者の予測
特に、データ解析についてはとても役立てることができているなと感じています。(本業がデータ解析であることからかもしれませんが・・・)
データ解析で使える点をざっくりまとめると以下の通りです!
これらを文章で指示をだすことだけで勝手に行ってくれます!
データ解析
今回データ解析をするにあたり、以下2つの準備が必要になります。
- 扱うデータ
- どのような背景、手順をまとめた「プロンプト」
実際につかってみる。
扱うデータ
今回は「Twitterの表示回数・いいね数」のデータを扱ってCpen Interpreterを動かしていこうと思います。
データ分析を依頼するプロンプト
以下のようにハッシュタグやアスタリスクを用いてまとめます。
## ***背景***
1ヶ月におけるTwitterの活動についての表示回数やいいねのデータがあります。
## ***手順***
1.tweet_activity_metrics_Seiyan1_20231005_20231102_ja.csvを読み込んで、データフレームとして読み込んでください。
2.いいね数が多いツイート本文を集計してください。
3.表示回数が多いツイート本文を集計してください。
4.表示回数が多い時間帯を集計してください。
5.集計した結果をグラフで表示してください。
6.これらのグラフと集計した結果から、どのようなことがわかるか、レポートを作成してください。
コードを実行する上でプロンプトというのは非常に重要です。指示は明確に、具体的に何をして欲しいのかを明確にすることで、綺麗に動くことができます。
例えばデータフレームにしたいときにも「〜を読み込んで、データフレームにして」とここまで言わなくてもできるのですが、「指示は具体的に」ということでこのような命令にしております。
そして、上のプロンプトのようにレポート作成までの手順を明確に指示をだしております。
実際の実行画面がこちらです。
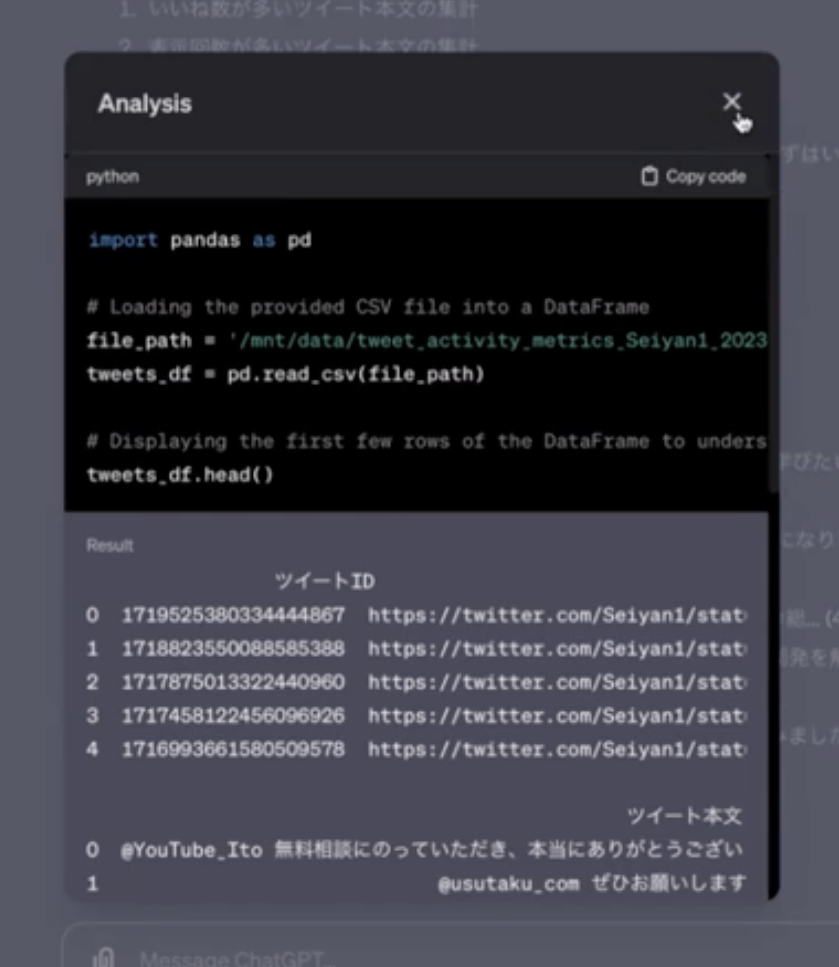
また、実行中の画面にある(青くなっている)部分をクリックすることで詳細やPythonのコードもみることができます。

※今回こちらを実行した際、実行が完了するまで、かなり時間がかかりました。時間帯やタイミングによっては今回のように時間がかかる場合がございます。
また、こちらの実行についてはOpen Interpreterの記事の方でも紹介させていただいております。Open Interpreterであれば処理が完了するまでの速度は速いです!
さらに、今回は「表示回数」という指示をだしたのですが、そのようなカラムは存在しません。しかし、ChatGPTが「表示回数」というのが「インプレッション」だと解釈して実行してくれています!
※画像はOpen Interpreterで実行した画像です。
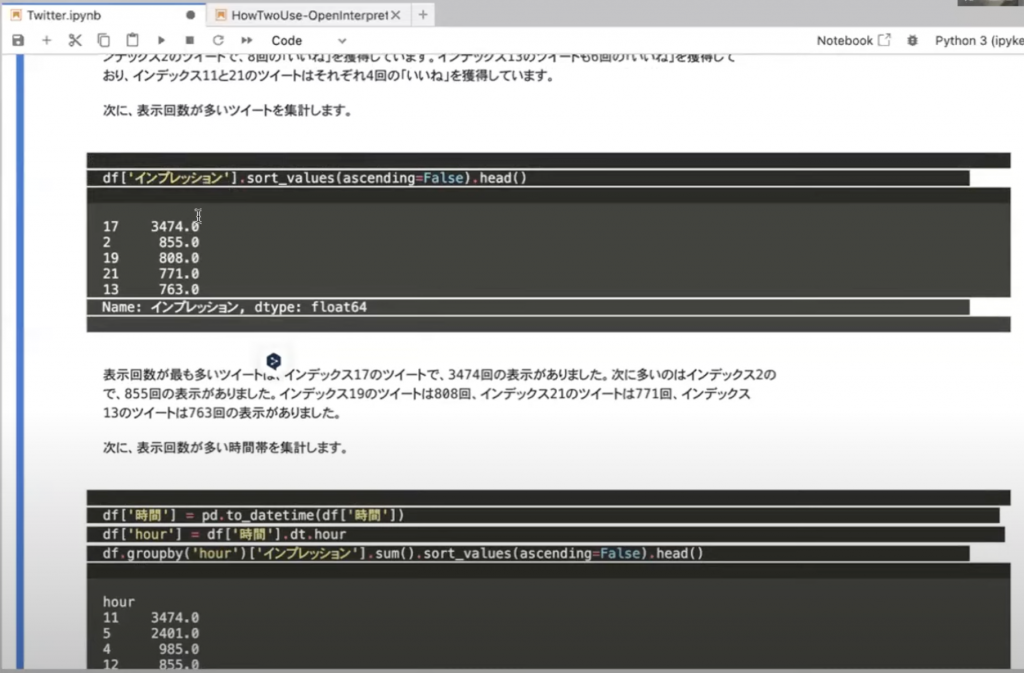
そしてこちらが、「いいね数」と「インプレッション」数のグラフです
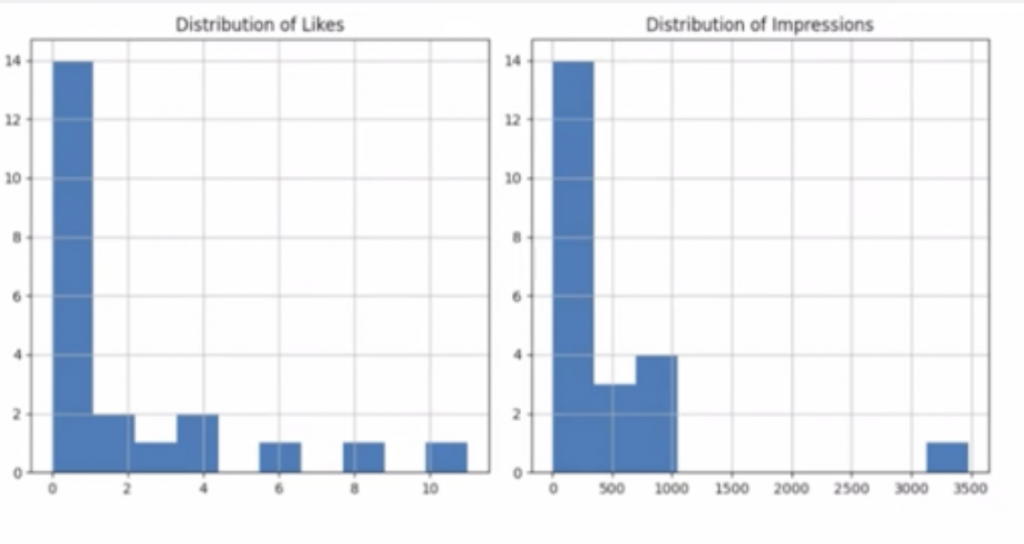
時間帯別のグラフです。(再生マークがありますが、画像です。)
そして最後には、このデータについての簡単なレポートを最後にだしてくれました。以上がデータ解析の流れです。
資料作成(評価△)
必要なパッケージをインストールして進めてくれるので、普段プログラムを書かない人も安心です。
プロンプトをしっかり書いても指示通り動いてくれないことがありますが、何度もやりとりすることで、指示通りに動かすことができる可能性を上げていくことができます!
また、長い指示だとトークン数の上限に達しているのか、ずっと実行中で止まることもありますので、資料が多すぎる場合は注意が必要です。
その他にも、python-pptxのパッケージでアウトラインをスライドにしてくれることはメリット☆
それでは、実際に行ってみます。プロンプトを用意し、実行します!
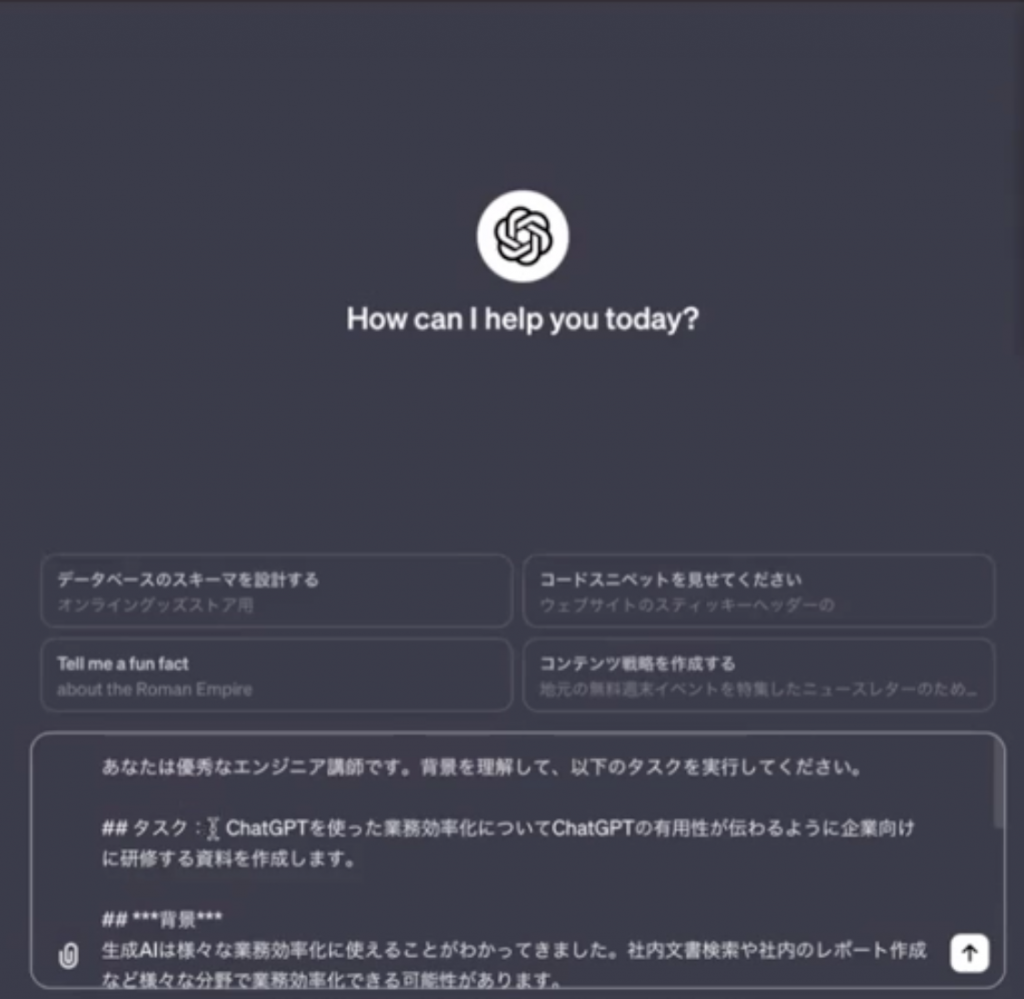
あなたは優秀なエンジニア講師です。背景を理解して、以下のタスクを実行してください。
## タスク : ChatGPTを使った業務効率化についてChatGPTの有用性が伝わるように企業向けに研修をする資料を作成します。
## ***背景***
生成AIで様々な業務効率化に使えることがわかってきました。社内文書検索や社内のレポート作成などさまざまな分野で業務効率化できる可能性があります。
各社、生成AIを導入にして生産性をあげたいが、どのようにつかっていけばいいかわかっていません。
そのためわかりやすくChatGPTや生成AIの使い方を解説するための資料を作成したいです。
## ***手順***
1.一般向けな企業向け研修資料のテンプレートを作成してください(ここは実際にアウトプットしないでください。)
2.生成AIの業務効率化の可能性をそのテンプレートに当てはめて、生成AIの業務効率化の可能性や事例が伝わるよう作成してください。(ここも実際にアウトプットしないでください)
3.企業向けの生成AIを使った研修資料を作成してください。
## output : 研修資料のアウトラインと中身を10枚のパワーポイント資料を作成してください。*ChatGPT業務効率化_ver3.pptx*として作成してください。
また、パワーポイントの資料についても20枚だとうまくいかないので、10枚と指示をしました。
以下、実行画面です。

このようにアウトラインというのをだしてくれます。これが、スライドの内容になってきます。
見栄えのいいデザインにすることはできませんが、資料作成の下書きぐらいにはなってくれそうです。一部を使って資料作成に役立てていくというイメージです。
完了すると以下のリンクからダウンロードができます。
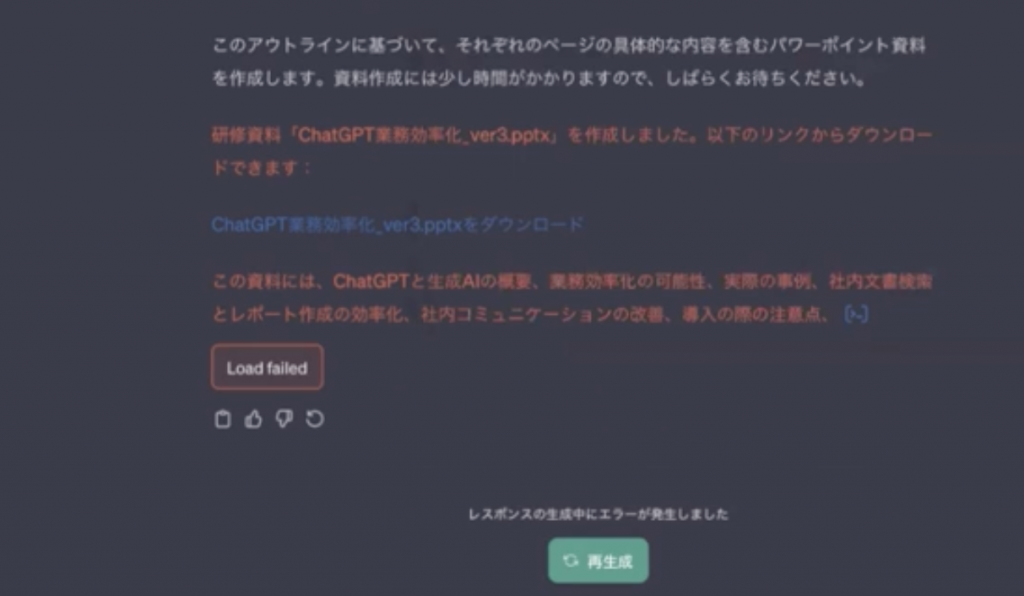
そしてできたスライドがこちらです。

こちらもChatGPTがPythonのパッケージ「python-pptx」というのを使って作成しております。
予測モデルの作成
ChatGPTを使って予測モデルの作成を試みたいとおもいます。今回扱うのはKaggleの一番最初にある「タイタニック」を使って乗客の生存確率モデルというのを予測していきたいと思います。
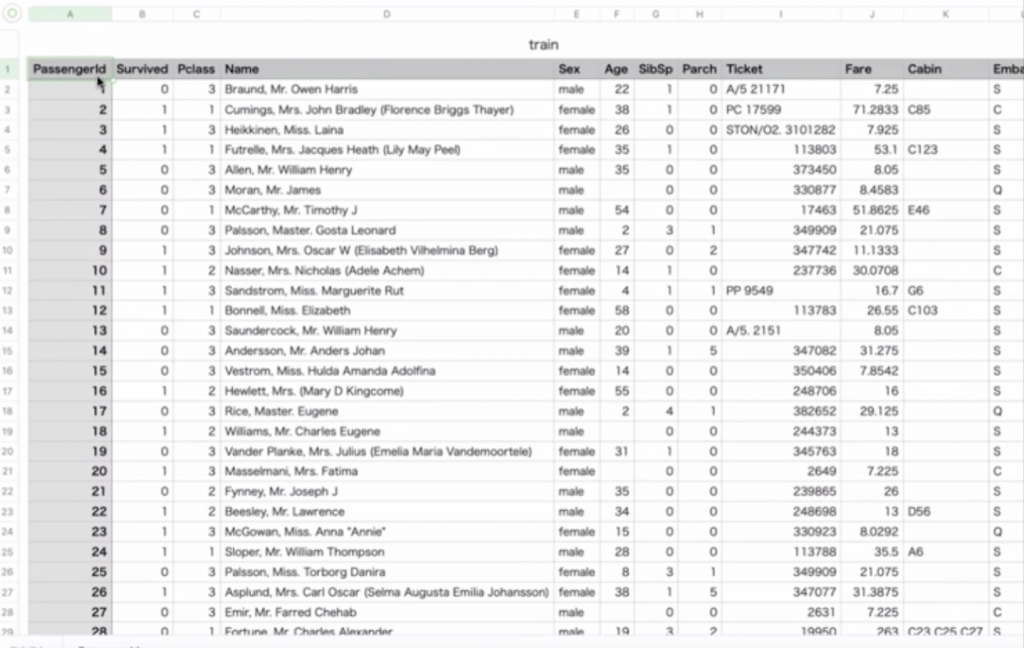
与えられているデータには「Survived:実際に生き残ったか」「Sex:男性か女性か」「Pclass:階級のランク」などがあります。
これらを使って、「階級の高い人は生き残りやすい」や「女性の方が生き残りやすい」や「赤ちゃんが生き残りやすい」といったものを調べていきたいと思います。
こちらも以前ではデータサイエンティストなどの方がコードを書いてさまざまな予測モデルを出してきたのですが、Code Interpreter を使えば簡単に予測モデルを作っていくことができます。
それではこの「train.csv」を読み込ませて実行していきたいと思います。
実際に実行すると、データが全て英語だったため、英語で実行されてしまいました。データによっては日本語表記でという命令もひつようになります。
データを見ると、欠損値についてもまとめてくれています。
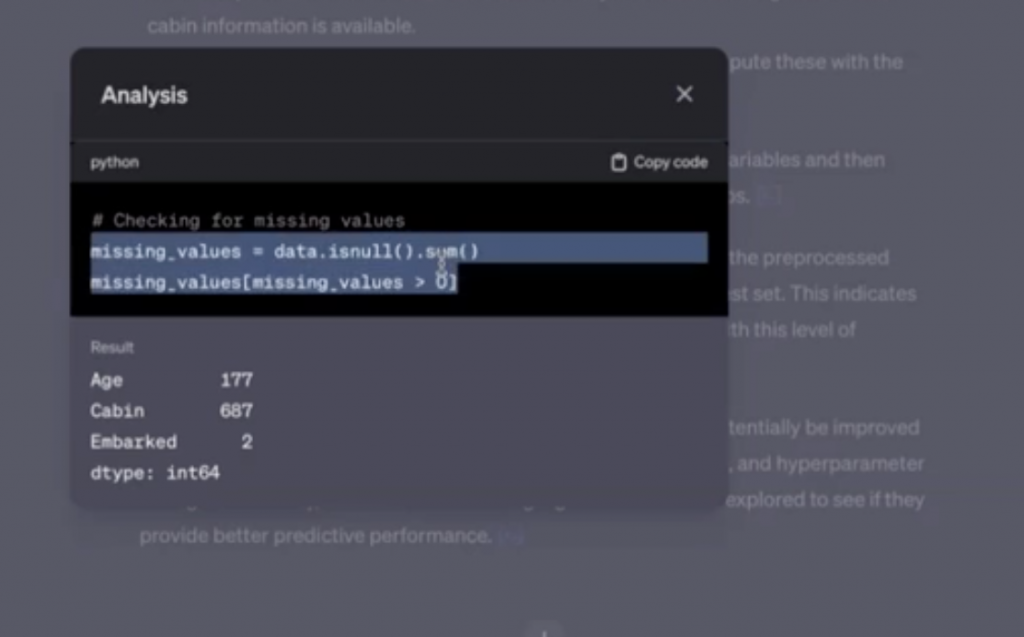
また、実際に予測モデルをだすためのPythonコードも書いてくれています。
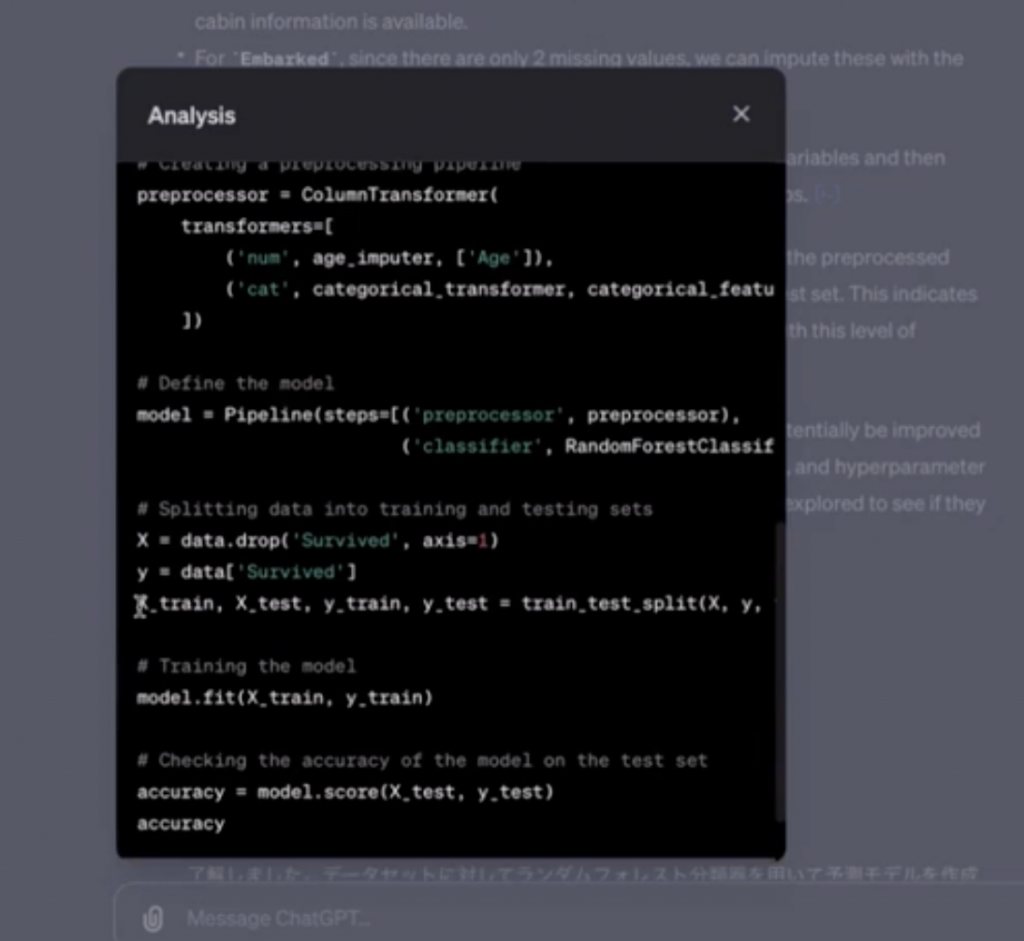
今回は「ランダムフォレスト」というのを用いて予測モデルを作成したようです。このモデルの予測的中率は約72.63%でした。ここからさらに精度を上げるには特徴量エンジニアリングだったり、ハイパーパラメータのチューニングが必要となります。

このようにデータサイエンティストがやっていたような業務がデータを用意して命令を出していくことで簡単にできてしまいます。
ChatGPT以前の自然言語処理の技術の概要
最後に技術的な背景、どういうことをして文章をコンピュータに解析させていたかについて解説させていただければと思います。
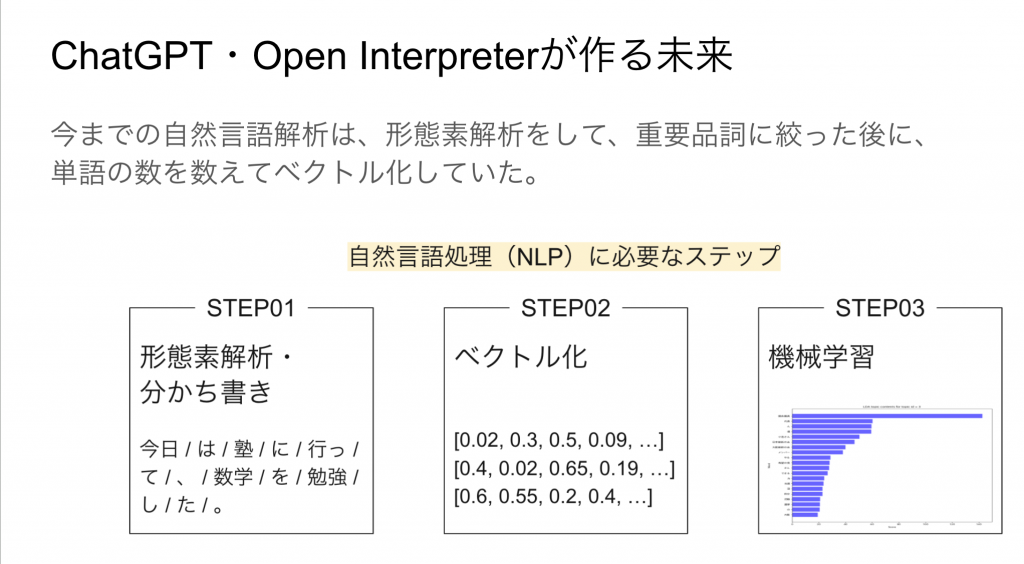
まず、ステップ1にある「形態素解析」というものを行います。意味のわかる最小単位に文章を分割することで、名詞、動詞、形容詞といった重要な品詞だけを絞り出します。
次にステップ2でその品詞をベクトル化します。文章を単語の出現回数に直します。例えば「Apple computer of the apple mark」という文章では「apple」という単語が2回出てきているので、ベクトル化する際に数値を2としております。その他も単語に応じて出現回数をカウントしていきます。
数値に直したらステップ3で先ほどの予測モデルを作ったような機械学習モデルで予測をさせていました。
この自然言語処理の問題点と現在
往来はこのような単語の出現回数からの機械学習が主流でしたが、問題点もあります。
例えば「私はりんごが好きです」「私はりんごが嫌いです」というのは意味としては正反対のことを言っています。しかし、単語の出現回数をベクトル化したデータでは、「好き」も「嫌い」も出現回数でしか表現されません。
そのため、文章の意味をコンピュータに解釈させることは非常に困難でしたが、ニューラルネットワーク‧ディープラーニングの手法が自然言語処理でも応用されるようになってきました。
これにより、文章の意味も数値で把握することができるようになってきました
さらにその先の未来
このような自然言語処理が可能になってくると、言葉でコンピュータを操ることができるようになってきます。

これは「ai pin」という小型の機械です。話しかけることでお気に入りのプレイリストの再生、買い物、電話等できます。このプロダクトが成功するか失敗するかはわかりませんが、GUIの概念がChatGPTだったり、Code Interpreterを触っていると変わってくるのだろうと思っています。文章で操ることができるようになることで、今後、UIが根本的に変わってくるかもしれません。
生成AIでできること
最後に自社内で実際に使っている生成AIについてのご紹介です。
こちらはMetaの記事ですが、ChatGPTに記事の翻訳と要約させて記事にしております。ニュースのリリースを自動化できることにかなり役立っております。
他にもメルマガなどさまざまな使い用途があるかと思います。もし、ご興味ございましたら、初期費用はいただく形になりますが、運用費はゼロですのでお問い合わせください。
質疑応答
Q1.同じことをやりたいと思います。プロンプトはどこから取得すればいいですか。
今回実際に使ったプロンプトについては私が作ったものになります。それについての共有は可能です。※記事のプロンプト部分をコピーしてお使いください。また、作り方についても記事の部分を参考にしていただければと思います。
以下、補足になりますが、最初に背景をかき、GPTの役割を規定してあげ、その指示を出して行くことがGPTの出力精度を上げる上で重要になってくると思います。
GPTのアルゴリズムはすごい知性があるように見えるため、すごいことが行われているというふうに思いがちですけど、裏側で行われていることは非常にシンプルです。
入力文に対してアウトプットで次の単語で最も確率が高いものを抽出して文章をどんどん作っているということを行なっているだけです。
例えば、「データ解析をするものです」や「あなたは医師です」みたいな役割を与えてあげることでその次の単語を予測する確率がより精度の高いものになってきます。
こういった背景をつけてあげるのが重要になってきます。背景があって指示があるというものがアウトプットの精度を高めるのに有効な手法になっております。
今回は以上になります。最後までお読みいただきありがとうございました。

