
公開日:2019/9/24
更新日:2019/9/24
キーワード:Python Webスクレイピング
文字数:4800(読み終わるまでおよそ8分)
この記事でわかること
- Pythonでスクレイピングする方法
- Googleスプレッドシートでスクレイピングする方法
はじめに
スクレイピングとは、ウェブサイトの情報を取得することができる技術のことです。スクレイピングと似た言葉でクローリングがありますが、クローリングとは、複数のウェブサイトのリンクをたどってウェブサイトを巡回することです。
クローリングで必要な情報があるウェブサイトを回り、スクレイピングでウェブサイトから情報を収集するというのが、Web上のデータを解析するのにしばしば採用されるプロセスです。
【注意点】
ウェブサイトによっては、無許可のクローリング・スクレイピングを拒否している場合があります。通常、そのようなサイトはスクレイピングできないようになっていますが、中にはそのような設定のない場合もあるので、スクレイピングを行う前にサイトのルールの確認が必須です。
1. Pyrhonによるスクレイピング方法について

では、Pythonでスクレイピングする方法を見ていきましょう。
1) 必要なライブラリ
今回は、RequestsライブラリとBeautiful Soupライブラリを使ってスクレイピングを行いますので、事前にインストールしてください。
pip install requests
pip install beautifulsoup4Requests はPython の HTTP 通信ライブラリで、各サイトからWebページを取得するためのものです。そして、Beautiful Soup は取得したWebページを解析して、情報を抽出するためのものです。
2) Requestsの使い方
Requestsライブラリを使用して、Webサイトから情報を取得する方法を見ていきましょう。例文2-1で日本経済新聞から情報を取得してみます。
<例文2-1>
import requests
# アクセスするURLを取得
url = requests.get("http://www.nikkei.com/")
#サイトの情報を表示
print(url.text)例文2-1の実行結果は、以下のようになります。(一部のみ)
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="ja" lang="ja" dir="ltr" id="R1">
<head>
<meta http-equiv="Content-Language" content="ja" />
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<meta http-equiv="Content-Style-Type" content="text/css; charset=UTF-8" />
<meta http-equiv="Content-Script-Type" content="text/javascript; charset=UTF-8" />
・・・(以下省略)Requests ライブラリを使って、日本経済新聞のサイトの情報を得ることができました。
3) Beautiful Soupの使い方
今度は、Beautiful Soupを使って日本経済新聞のホームページから、日経平均株価を取得してみます。
まずはブラウザで、日本経済新聞の株価のページを見てみましょう。
著作権の関係で、ここではホームページは掲載しませんが、ページの中央付近に日経平均株価が載っています。
この日経平均株価を右クリックして、メニューから「検証」を押してみてください(図1)。
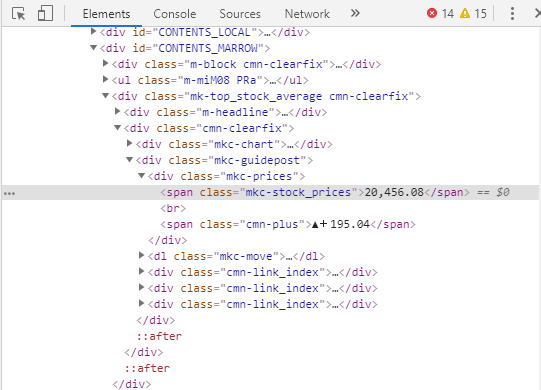
span要素がハイライトされ、Class=”mkc-stock_prices”となっていることが分かります。株価の位置が分かったので、”mkc-stock_prices”を手掛かりにスクレイピングで情報を採取します。
<例文3-1>
import requests
from bs4 import BeautifulSoup
# アクセスするURL
url = "http://www.nikkei.com/markets/kabu/"
# URLにアクセスするURLを取得する
html = requests.get(url)
# BeautifulSoupで扱う
soup = BeautifulSoup(html.content, "html.parser")
# span要素全てを摘出する
span = soup.find_all("span")
# print時のエラーとならないように最初に宣言しておく
nikkei_heikin = ""
# for分で全てのspan要素の中からClass="mkc-stock_prices"となっている物を探す
for tag in span:
# classの設定がされていない要素は、エラーとなるため、tryでエラーを回避する
try:
# tagの中からclass="a"のaの文字列を抽出する
# get関数では配列で返ってくるので、pop(0)で配列の最初の要素を抽出する
# 複数のクラスが設定設定されている場合があるので、このようにしている
price = tag.get("class").pop(0)
# 抽出したclassの文字列が、mkc-stock_pricesと設定されているかを調べる
if price in "mkc-stock_prices":
# mkc-stock_pricesが見つかったら、tagで囲まれた文字列をstringで取り出す
nikkei_heikin = tag.string
# 抽出が終わったのでfor文を抜ける
break
except:
# エラーが生じたときはパスして、次のサイクルへ移動する
pass
# 抽出した日経平均株価を出力する
print(nikkei_heikin)20,456.08日本経済新聞の株価のページから、日経平均株価を取り出すことができました。
今回はある時点の株価を取り出すだけのコードですが、コードを改良することで、1時間ごとに自動で株価を取得してcsvに書き込むといった複雑な処理も、可能となります。
4) スクレイピングするための必要な知識
自分の欲しい情報を適切に取得するには、Webに関する知識がある程度必要となります。具体的には、Webページを作るための基本的なマークアップ言語であるHTML、ウェブページのスタイルを指定するための言語であるCSS、サイトによっては動的処理のために用いられるJavaScriptの知識です。
これらの知識は全くなくても、スクレイピングはできなくはないですが、自分が欲しい情報を確実に得るためには、最低限の知識が必要となるので、スクレイピングに本格的に挑戦しようと思っている方は、是非これらについても勉強してください。
2. GoogleスプレッドシークレットによるWebスクレイピング

スクレイピングはPythonでないとできないというわけではなく、Googleのスプレッドシートでもスクレイピングを行うことができます。
Googleスプレッドシートと言えば、MicrosoftのExcelの無料版のような位置づけですが、スクレイピングに有効な関数を持っているのが特徴です。
そこで、スプレッドシートを使ったスクレイピングを紹介します。
QiitaのAdvent Calendar(2018)を素材とし、投稿一覧のリストを抽出してみます。なお、スクレイピングを行うにあたり、以下の条件を設定しました。
- Googleスプレッド関数のみを使う
- セルA1に入力されたURLを使い、記事作成日、記事のURL、記事のタイトルを抽出する
1) IMPORTXML関数を使ったタイトルタグの取得
Googleスプレッドシートには、さまざまな種類の構造化データからデータをインポートできるIMPORTXML関数という強力な関数があります。
セルA2に以下の関数を入力することで、セルA1の<title>タグの中身を取得してくれます。
=IMPORTXML(A1,"//title")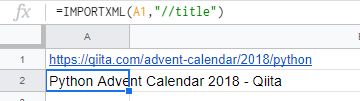
2) 作成日の取得
ページの下の方に、作成日、作成者、タイトルのリストがありますので、ここから作成日を取得してみます。
作成日を右クリックして、メニューから「検証」を押してみると、作成日のクラスは、class=”adventCalendarItem_date”であることが分かります。
そこで、IMPORTXML関数を使ってセルA5に以下を入力すれば、12/1~12/25をまとめて取得してくれるので、とても便利です。
=IMPORTXML($A$1,"//div[@class='adventCalendarItem_date']")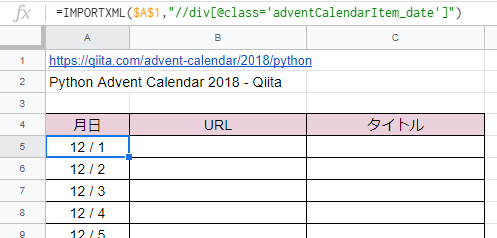
クラス名をダブルクォーテーションにしてしまうと、関数の引数のそれと重複してしまうため、シングルクォーテーションにする必要があります。
3) 記事のURLとタイトルの取得
記事のURLとタイトルは、作成日と同じように簡単に取得できます。
- URLの取得(セルB5に入力)
=IMPORTXML($A$1,"//div[@class='adventCalendarItem_entry']/a/@href") - タイトルの取得(セルC5に入力)
=IMPORTXML($A$1,"//div[@class='adventCalendarItem_entry']/a") 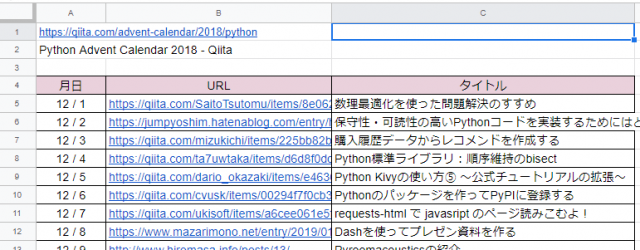
このように、Googleスプレッドシートでも簡単な関数でスクレイピングは可能ですので、Pythonを使うのはちょっと・・・という方は、Googleスプレッドシートの活用を考えてください。
3. おわりに
今回は、PythonのRequestsとBeautiful Soupを使ったWebスクレイピングの例を紹介しました。Beautiful SoupでWebサイトの色々なデータを取り出せるので、Webに掲載されているデータを収集して、機械学習でモデリングするといったことも可能となります。
Webサイトからデータを取れるようになると、データ収集の幅が広がるので是非スクレイピングにチャレンジしてみてください。
また、Googleスプレッドシートでもスクレイピングはできますので、Pythonを使うのに抵抗を感じる方は、Googleスプレッドシートでのスクレイピングに挑戦してみてください。
なお、冒頭でも述べましたが、スクレイピングを禁止しているサイトもあるので、スクレイピングを行う前にサイトの規約をよく確認してください。
4. 参考サイト
【初心者向け】PythonでWebスクレイピングをしてみよう!手順まとめ
https://www.sejuku.net/blog/51241
Python Webスクレイピング 実践入門
https://qiita.com/Azunyan1111/items/9b3d16428d2bcc7c9406
Pythonでスクレイピングを行う方法【初心者向け】
https://techacademy.jp/magazine/18875
【Python】BeautifulSoupライブラリを使ってWebスクレイピング入門
https://code-graffiti.com/beginner-web-scraping-in-python/
SpreadSheetでスクレイピング。Importxml他、便利な関数9+1
https://qiita.com/ktmg/items/d53440c913e20f8bb34c
【スクレイピングツール】面倒な情報収集はGoogle Spreadsheetにやらせよう!
https://dividable.net/googleappsscript/scraping-tool/
