
2024年もChatGPTの勉強会にてたくさんの機能を発信していこうと思います!みなさんどうぞ、よろしくお願いします。
本日はアステリア株式会社森一弥様にRAGの使い方について、解説していただきました。
チャットボットを作成する際に、RAGの知識は欠かせません。この記事はそのイベントレポートになります。それでは解説を始めていきます。
自社データを扱う上で
様々な方法があるかと思いますが、まずはこの4つについて解説します。
① ファインチューニングで追加学習
② プラグインの利用
③ ノーコード(GPTs)で開発
④ 前提知識を使ったプロンプトエンジニアリング
ファインチューニングで追加学習
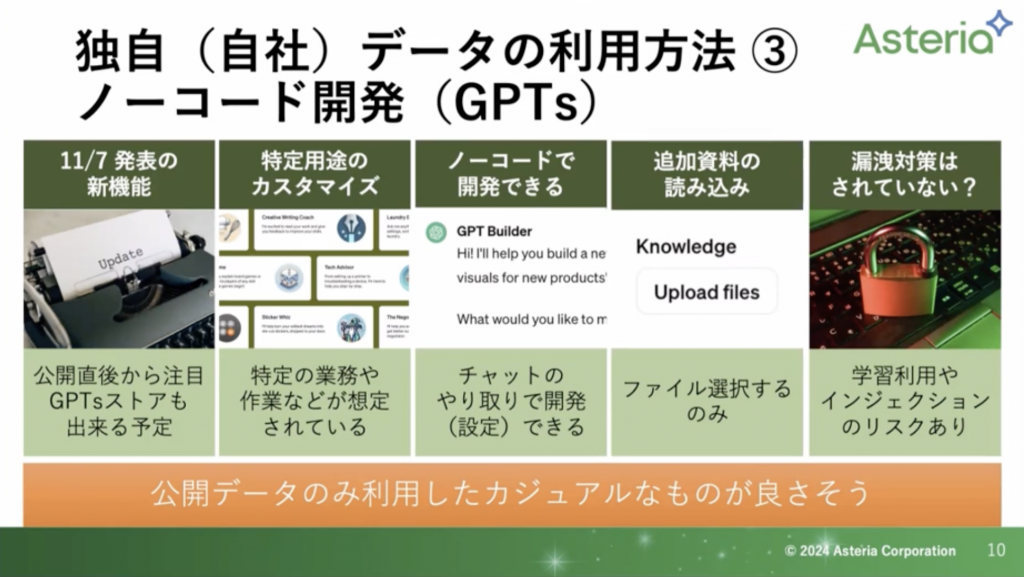
ファインチューニングですが、1つの会社で使うといよりかは、1つの部門で扱いたいなど、業界用として扱う方が向いているという話があります。(医療系、建築系など)なので、自社データを扱うというのにはあまり向いていないかなと思っています。
ファインチューニングは、学習済みモデルをあらかじめ用意しておき、GPT3.5や4のそれぞれのモデルに追加で学習させる方法になります。
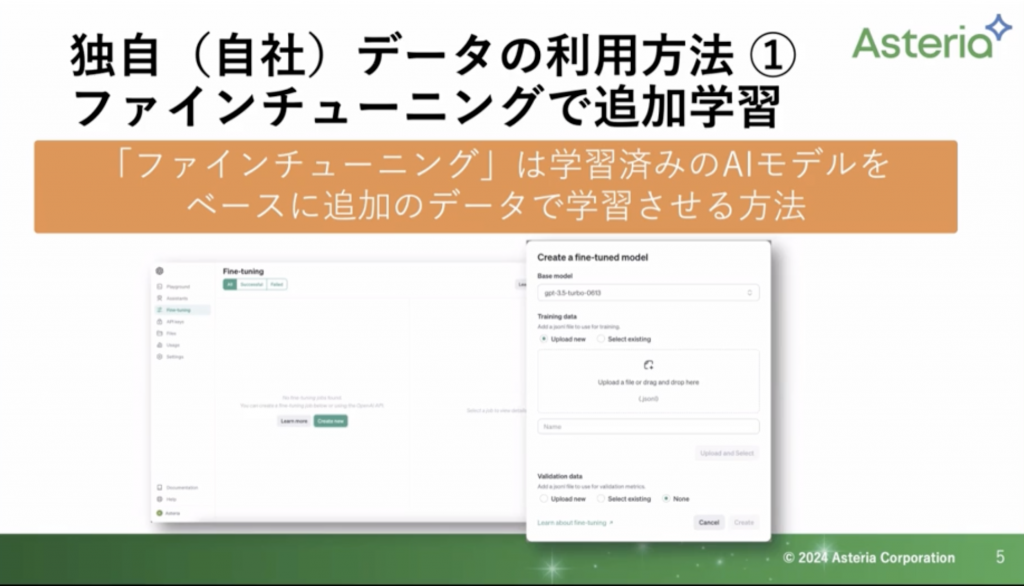
少し前まではAPIを使って、プログラムから自社のデータを読み込ませて作っていくという形でした。
ここ最近ではOpenAIの画面からできるようになりました。しかし、ファイルの制限(JSONL形式)があります。ですので、そちらに合わせて変換する必要があります。
ですので、自社データを扱うには「PDFデータがある」といったことではなく、プログラマーさんたちが扱うものに変換しておく必要があります。

学習の精度についてですが、GPT3.5でもファインチューニングは行うことができます。しかし、思ったような解答が得られないというのが、私の主観です。
それなら4.0でと思ったのですが、すべての人に許可が降りているわけではないです。大規模のデータを持っている大手の会社のみが扱うことができます。そのため、私もまだ触れてはいません。
また、情報漏洩についてですが、APIを使っての操作であれば、そこまで心配する必要はないかなと思っています。しかし、OpenAIの画面ではどのように扱われるか記載がないため、これについてもわかりません。
まとめると
・ファインチューニングとは、自社データを使ってモデルをさらに学習させる方法
・自社データを扱うというより、1つの業界で扱う方がよい。それでも扱う場合はPDFとかではなく、JSONLになおす必要がある。
・GPT4ではまだ使えない。3.5では扱えるが、精度があまりよくないと感じる。
プラグインの利用
こちらはGPT4のみで扱えます。
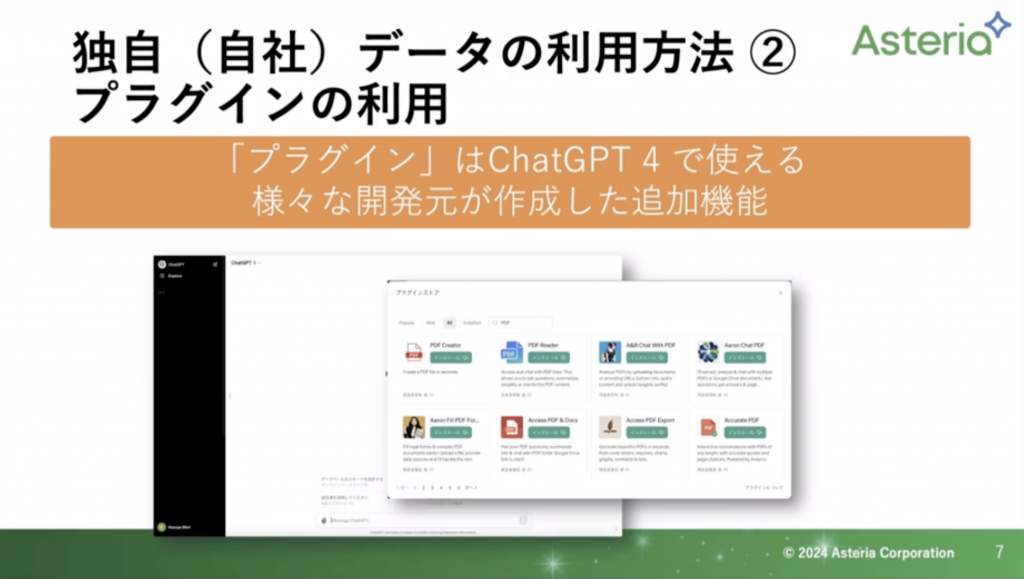
手元にPDFやワード、エクセルのデータがあればそちらを使って扱うことができます。
また、1つ1つファイルを選択して行なったり、ファイルの数に上限があるため、個別になっているファイルデータを複数選択するものについては向いていません。
また漏洩対策として、ChatGPTの管理画面にある「チャット履歴とトレーニング」というのをオフにすれば漏洩対策を行うことができます。

一人(1担当者)で扱うには良いのかなと思っているのですが、チームで扱うとなると扱いづらい部分があるかなという印象です。
ノーコード(GPTs)で開発
こちらも有料版のみの機能になります。会話のやりとりで「このデータを扱いたい」などの命令でボットを作成していきます。ボットになるので、チーム内での共有も容易です。また、今年に入って「GPTs Store」が始まりました。他の方が作成したボットを購入できる仕組みです。
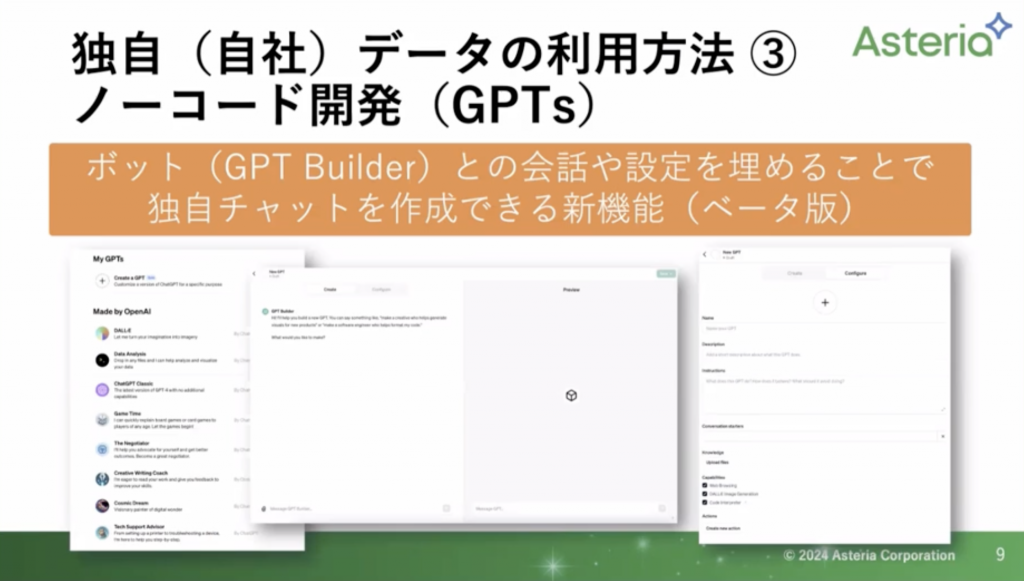
いろいろな方に提供できる点から、自社内で使うというよりは個人に合わせて使いやすいように提供していくツールになります。
また、出たばっかり(2024年1月24日現在)になりますので、情報漏洩のリスクもございます。インジェクションというものを自分である程度行なっていく必要があります。
前提知識を使ったプロンプトエンジニアリング
早速事例から入るのですが、「新しく購入したPCでのプリンターの接続方法を教えてほしい」という質問のやりとりを行います。
いきなり解答に行くのではなく、まず画像左下をご覧ください。
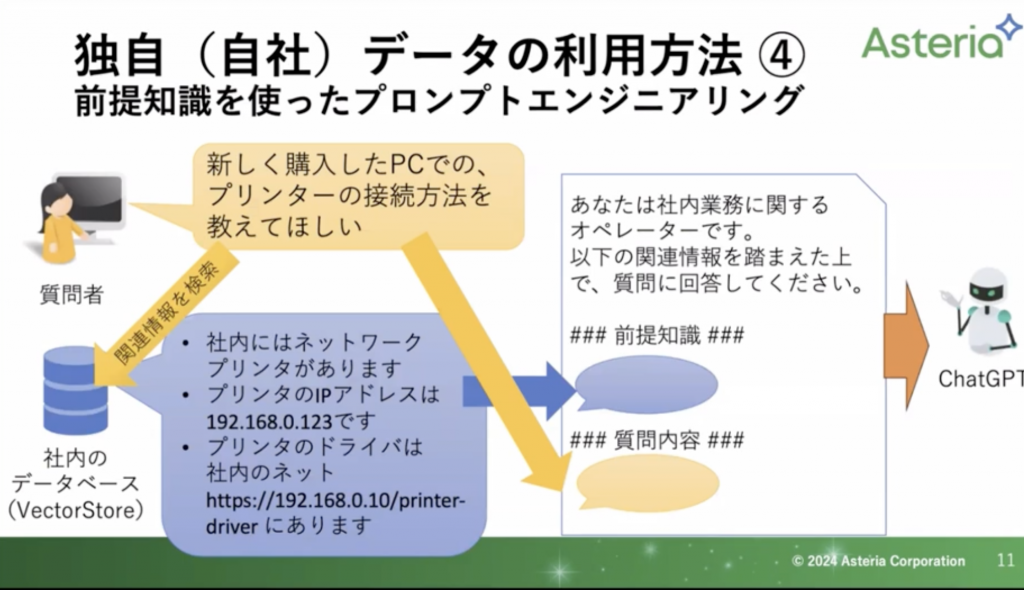
こちらの社内データベースにまずは検索にいきます。こちらは社内で容易された「Vector Store(ベクターストア)」と呼ばれるものです。
今回は画像にある通り、3つの解答がかえってきました。
・社内にはネットワークプリンタがあります。
・プリンタのIPアドレスは192.168.0.123です
・プリンタのドライバは社内のネットhttps://192.168.0.10/printer-driverにあります
これを元にした画像右のプロンプト作成に入ります。
このように予めの前提知識を入れてあげることで、その知識をもとに解答を作成してくれるようになります。
解答の元になるデータをベクターストアと呼ばれるデータベースに数値に変換して保管しておき、質問文が来た時にそれと照らし合わせて近い数字のものを解答とする。
この流れのことをRAGと言います。
まとめると以下の画像の通りです。
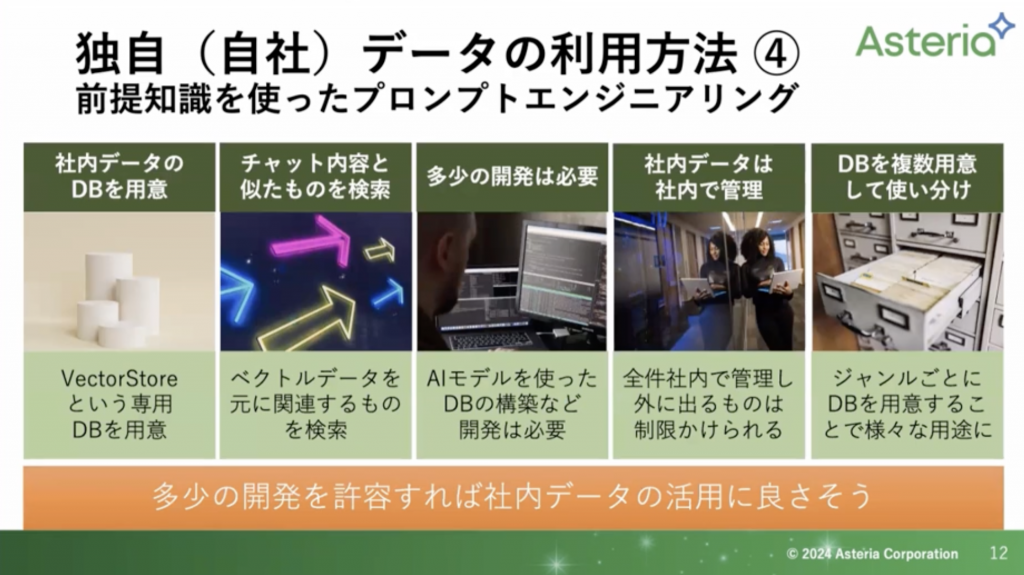
左二つがRAGの仕組みになります。(ここを詳しく説明していきます。)
また、これを仕組み化する必要があるため多少の開発は必要になります。そして、社内にデータは保管しているので漏洩の心配はありません。さらに、必要に応じてジャンルに分けてデータベースを複数で管理しておくと、より精度の高いものとすることができます。
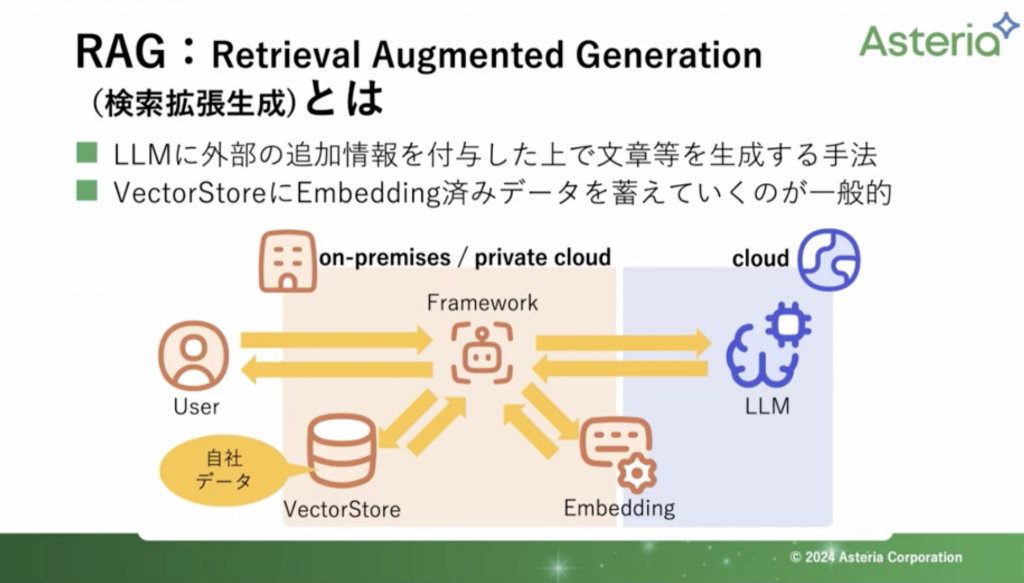
RAG(Retrieval Augmented Genaration)
RAGとは以下二つのことを言います
・LLM(大規模言語モデル)に外部の追加情報を付与した上で文章等を生成する手法
・Vector StoreにEmbedding済みデータを蓄えていくのが一般的
このEmbeddingというのが文字列を数値化する仕組みのことをさします。
RAGを使う理由
RAGを使う理由として、多くの会社さんは「自社データ」は「自社内で管理」したいことかと思います。また、ベンダーロックインしない(ChatGPTだけでなく幅広く、他のものにも扱うことができます。)ので、特定の環境に依存しません。そして、AIモデルに向上が見られた際には該当箇所のみ変更することができます。
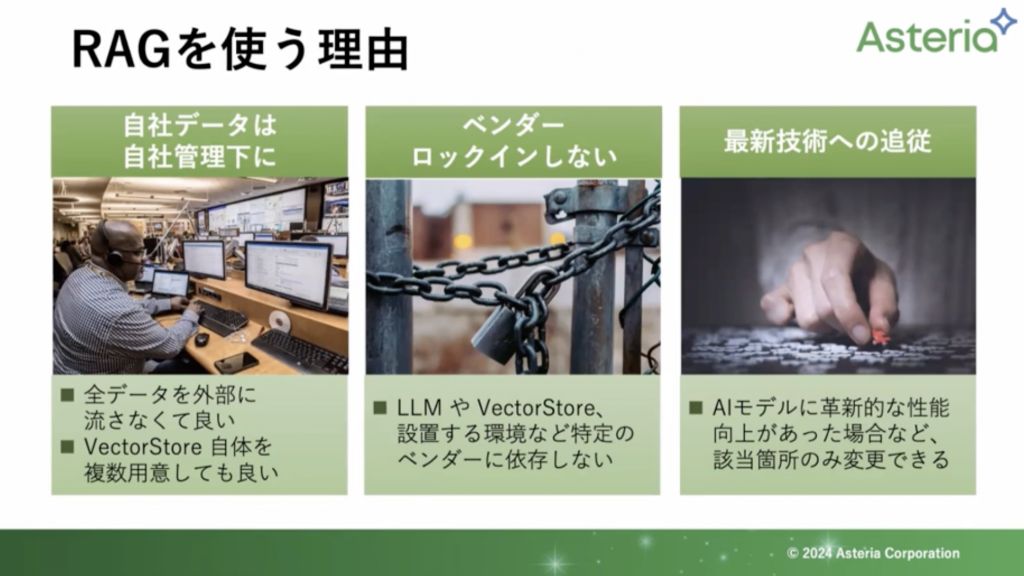
なので、もし、ChatGPTよりもGoogleのLLMモデルが良いものとなった際にも容易に変更することができます。
RAGの各構成要素と選択肢(フレームワーク編)
今日、ぜひ覚えてもらいたいのが「LangChain」になります。こちらは「Python」と「javascript」で扱うことができます。
自社環境でLLM、Embeddingを利用するのであればPython版を利用するのを勧めています。
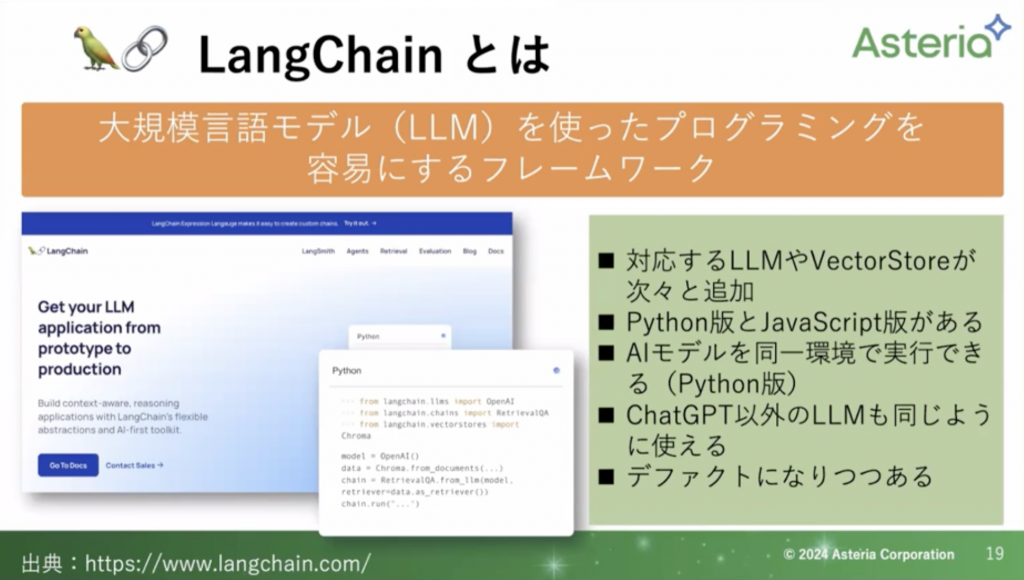
LangChainはChatGPTだけでなく、他のLLMも扱うことができます。ぜひ一度調べてみてください。
RAGの各構成要素と選択肢(LLM)
RAGは「ChatGPT」だけでなく、他のLLMモデルでも扱うことができます。日本でも独自の言語モデルというものを開発していることを耳にしたことがある人もいるのではないでしょうか。
ですが、やはり精度はまだChatGPTには届きません。現状ではAPIを引っ張ってきて扱うのが一般的かなと思っています。

RAGの各構成要素と選択肢(Embedding)
自社データの言語データを数値化するEmbeddingについてです。こちらもいろいろな種類がありまずが、おそらく日本語版を扱うと思うので、限定的になるかと思います。さらにフリーのものとなるあまり選択肢がありません。
しかし、こちらは「似たようなもの」を拾えてくればよいので、LLMみたいに流暢な日本語である必要はありません。なので、LLMよりも選択肢がございます。
こちらについては「HuggingFace」というサイトでいろいろなモデルを見ることができます。(後ほど紹介します。)

OpenAIのAPI利用料について
こちらも少しの工夫で利用料を抑えることができます。ざっくり言いますと、日本語だと1文字1トークンになりますが、英語だと1単語1トークンになります。
ですので、全部英語は無理でも、最初の案内を英語にするだけでも利用料を抑えることができます。
HuggingFace
こちらはLLMやEmbedding、画像生成など、さまざまなモデルを公開しているサイトになります。
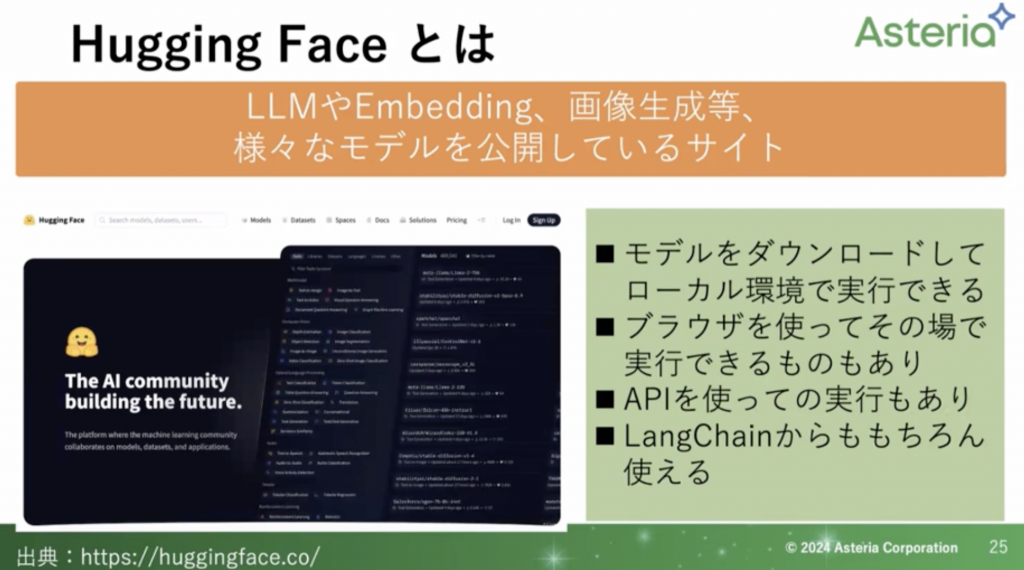
こちらもたくさんのものがありますので、ぜひサイトを覗いてみてください。(https://huggingface.co/)
RAGの各構成要素と選択肢(Vector Store)
こちらは名前の通り、ベクトル化したデータ(Embeddingしたデータ)を保管するデータベースになります。

特に、RDBから派生したものであれば既存のSQLと合わせて使うことができますので、SQLに長けているエンジニアさんが行えば開発時間を短縮できるのではと考えています。
Vector Storeも種類がさまざまありますが、ここでは一部紹介します。
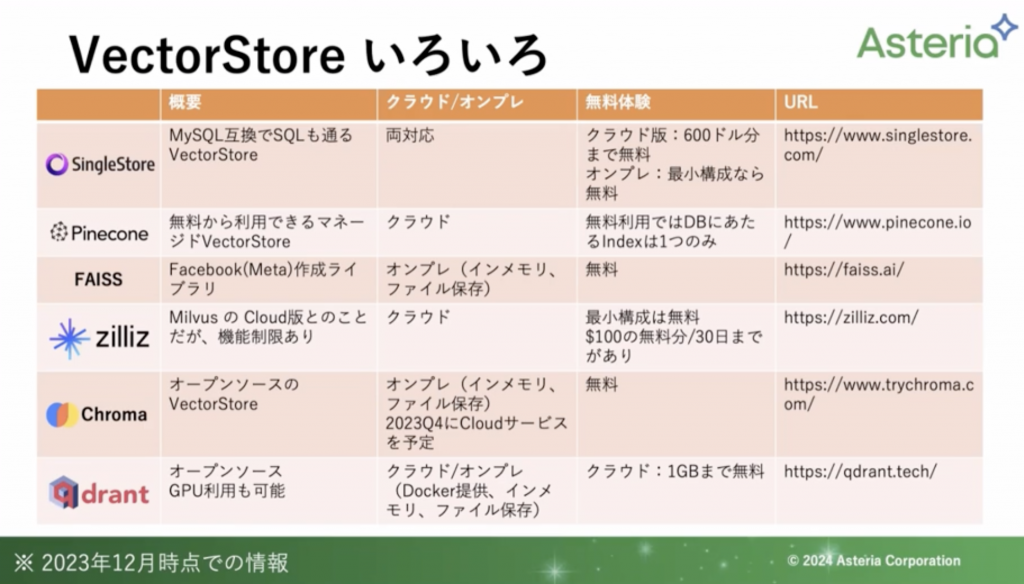
無料のものから有料のものまでさまざまございます。自分の利用用途に合わせて扱うと良いかと思います。
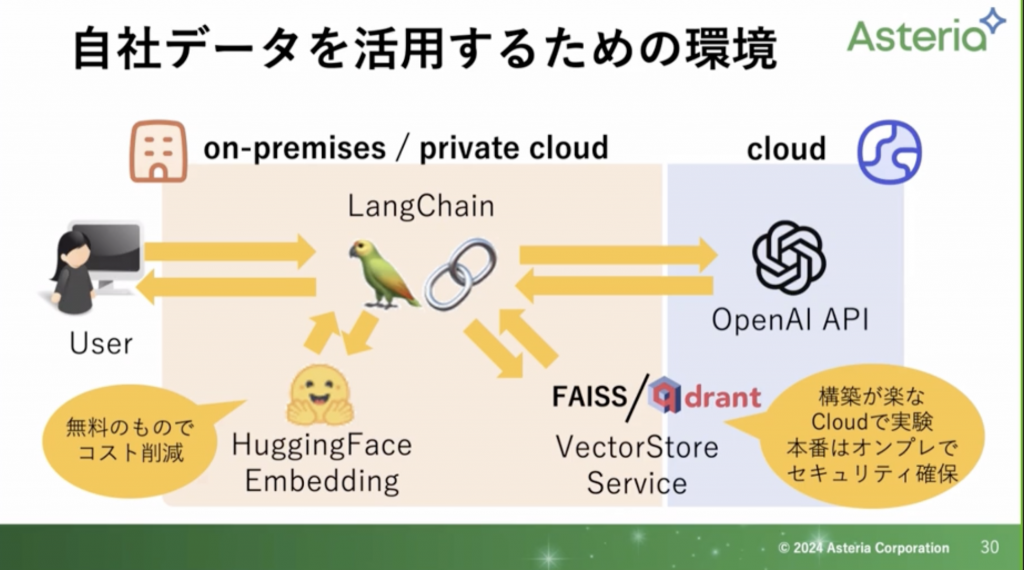
コスパとセキュリティを考慮したRAG環境
以下の画像にまとめました。
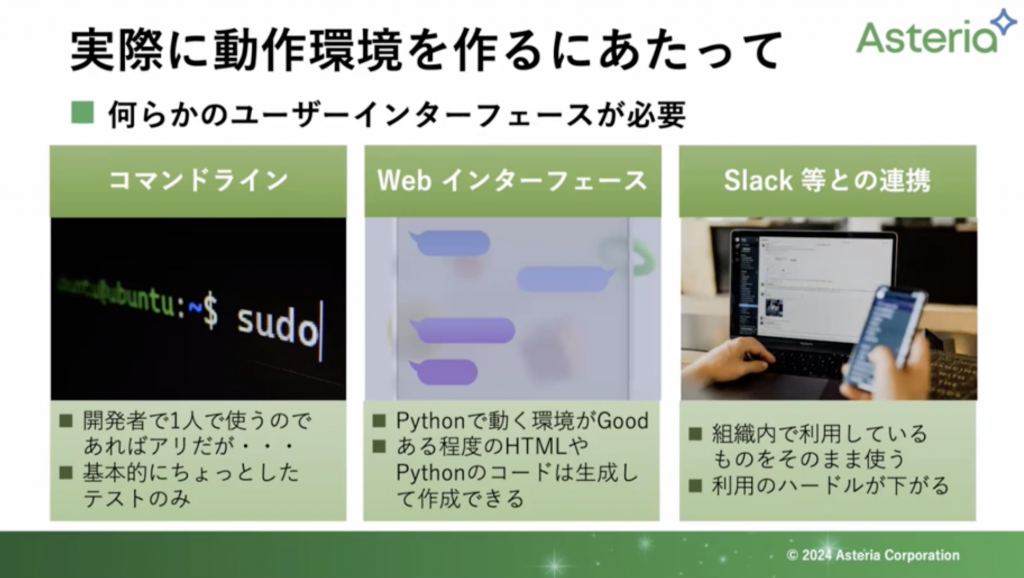
実際に動作環境を作るにあたって
自分一人で扱うのであればコマンドラインなどで済むかもしれませんが、複数で扱う場合にはインターフェースを考えていく必要があるかと思います。なので、HTMLだったり、Pythonのコードが必要になってくるかと思います。
もちろん、これらもChatGPTで生成することができます。他にもSlack等、社内SNSと連携することによって利用のハードルは一気に下がるのかなと思います。
「Lang Flow」について

ノーコードの環境があると便利かなと思い、実際に私も使っています。(LangFlowはまだベータ版です)
左側画面中央にダイアログみたいなものがあるかと思います。そこには、「LLMがこれを選んで、Embeddingのエンジンがこれを選んで、OpenAIのAPIキーがこれで」と画面の設定だけでできるようなものとなっています。
また、画像右側は弊社の製品になりますが、PDFやワード、エクセルといったデータを集めて、一つのVevtor Storeに入れるというのが容易にできるものとなっています。こちらの製品はデータ連携市場No1をいただいております。
やはり、自分たちが期待する解答を得るには設定値を変えるといった試行錯誤のしやすさが大事かなと思います。通常だとプログラムで行うかと思いますが、こちらでは画面の設定で行うことができます。
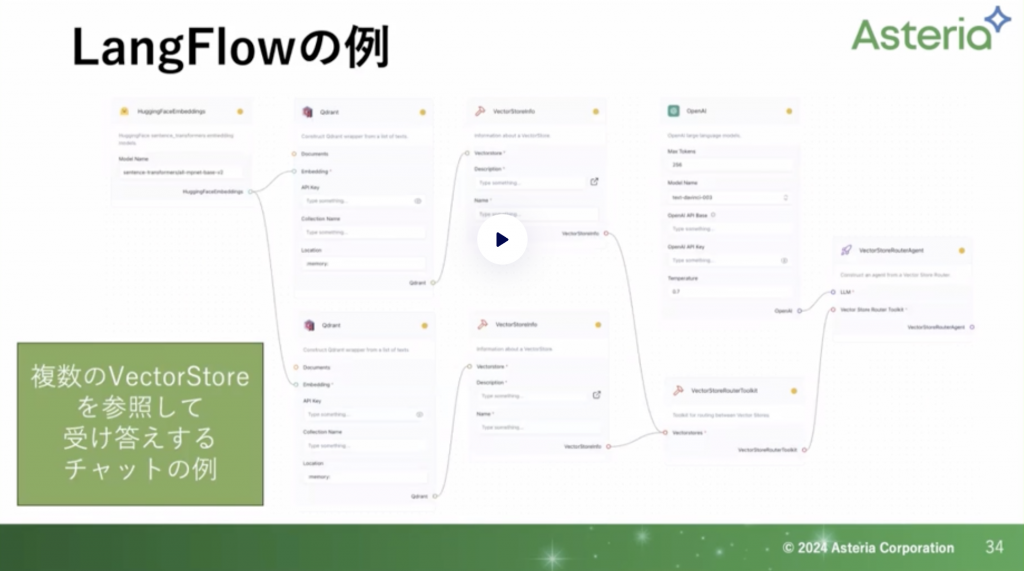
複数のベクターストアを使うとなると、このぐらいのボリュームになります。LangFlowを使えば直感的に扱えるかなと思います。

LangFlowで出来上がったものはすぐにChatで試すことができます。日本語入力も一応は通ります。エラーも表示はされないされないですが、試行錯誤はしやすいです。
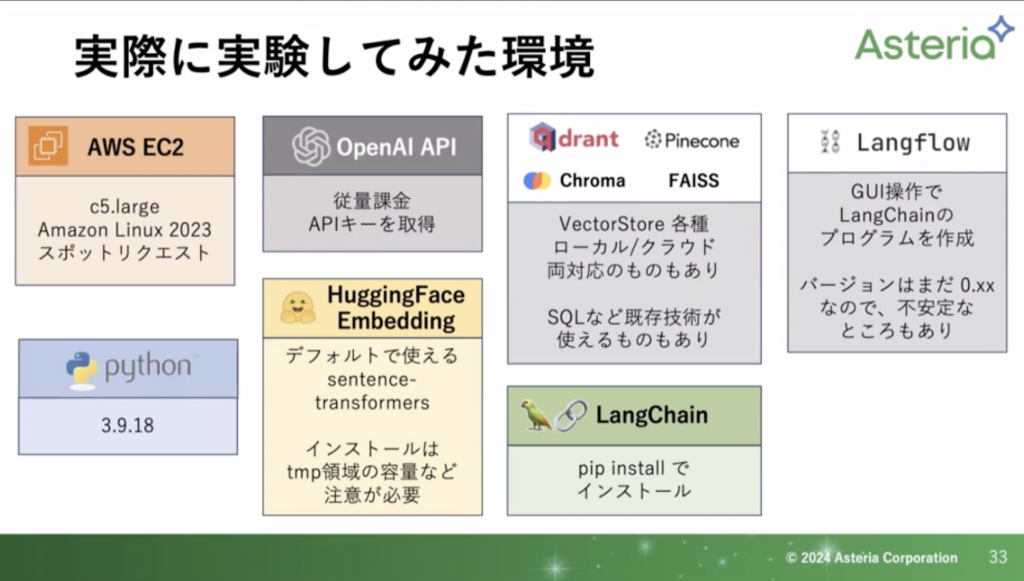
実際に色々と実験したてみた環境
以下の画像にまとめてあります。
特定のPythonのバージョンに対応していなかったりと、AWSの仮想環境の容量も気にしながら作成いたしました。
これらの作業に長けている人であれば半日程度でできるかなと思います。
まとめ

自社データを扱ったボットを作成したい場合はRAGをぜひ、検討してもらえればと思います。作り方によってはコスパだったりデータの管理、置き場を意識することができます。
さらに、RAGはChatGPTだけでなく、他のLLMにもカンタン(1行変えるだけなど)に対応できます。
ぜひ、まずはカンタンなデータを使って動かしながら作成していただければと思います。
質疑応答
Q1 エクセルのチャンクのサイズは?
バージョンの更新が早い為、一概にこれぐらいが良いというのが言いづらいです。いずれは全部入れても良いぐらいの分量にもなり得るのかなと思っています。
ですが、一つの文に複数の意味をもつようなものだと精度が落ちてしまうので、その場合はしっかりと意味のある単位で分けて入れるのが良いかなと思います。
Q2 検証でRAGを構築しましたが、Vector Storeで検索する精度があまりよくありません。整備された構造データではなく、社内のストレージサービスに散財する非構造データを一括でEmbeddingさせています。検証いろいろされているかと思いますが、どのくらいの精度感でしょうか。精度を求めるならやはり構造化データなのでしょうか。
構造化なのか、非構造化なのかはあまり考えていません。「社内のストレージサービスに散財する」とあるので、おそらくいろんなデータや情報が混在しているのかなと思います。ジャンルの違うものについてはしっかりと分けておくと良いと思います。複数のVectorStoreを用意しておくことで、質問に対してその内容に即したVector Storeに答えを拾いに行くというkとおができるようになるかと思います。
Q3 Vector Storeからの出力は普通のテキストという認識でよろしいのでしょうか?
はい、入力も出力もテキストという認識で大丈夫かなと思います。Vector Storeに入る際に数値化されていますが、LangChainを使っていればテキスト(日本語)になって戻ってきます。
Q4 LangChainでRAGを構築する場合、ChatGPTとオープンソースのLLMではまだ大きな差があるのでしょうか?(英語でのQAとサマラーゼーションの使用が前提で、ソースは手持ちのPDFやウェブ情報です。haggingFaceでおすすめのモデル等はありますか。)
日本語の流暢さ加減、良い感じの解答を求めるのであればChatGPT、や GoogleのLLM(google bird)が良いと思います。オープンソースですとどうしても学習されているデータが大きいと持ってくることができません。そして大手に勝つこともできません。そのため、かなり差があるかと思います。haggingFaceについてはLangChainでデフォルトで設定されているものを触った程度なので、手元に持ってくるものというので印象は特にないです。
Q5 Embeddingの際にドキュメント内で取り扱われる専門用語の略語(誤字脱字)などが入れられると検索結果にひっかからなくなると思います。(表記揺れ問題)このあたりの対応についてお願いします。
厳密にいうとそうなのかもしれませんが、1文字程度違うだけなら案外引っかかってきます。例えば音声入力でやる際に自動でやるとどうしても誤字が入ってきます。そういうのでもちゃんと答えが返ってきたりしています。なので、誤字を1個ずつ直すというレベルにしなくても大丈夫だと思います。当然きっちりしている方が良いのですが、まずはご自身のデータを放り込んで具合を見るのが良いかと思います。それで精度が出ない場合、初めて手をつけるというぐらいで良いかなと思います。
Q6 検索時のEmbeddingで時間がかかりそうですが、体感的には全文検索と比べてどうでしょうか?
Embeddingの検索自体ではあまり時間がかからないのですが、それを含めて、全体通すと遅いなと感じることは結構あります。クラウドですので、どうしても早い時と遅い時というのがあります。ですので、普通の検索エンジンと比べるとどうしても遅くはなります。
今回でた質問はしっかりと使われている方の質問が多かったですね。次回の勉強会についても以下のリンクより受け付けております。ぜひまたお会いしましょう!
【LLMを触ろう!!!】
https://chatgptllm.connpass.com/

