はじめに
今回は、「レコメンド」を見ていきます。ECサイト等で、過去の顧客の購買履歴をもとに好みを分析し、顧客が興味・関心がありそうな情報を個別に提示することで、それらのサービスを「レコメンデーション」と言います。
顧客にとっては、自分が好きな情報に効率よくアクセスできる可能性が高めることができ、情報を提供する側にとっては、顧客の購買率を高めることが期待できます。レコメンデーションは、顧客満足の向上と販売促進との双方を兼ねたサービスの手法として、特にネットショッピングの世界で急速に普及しています。
レコメンドの詳細
レコメンドのアルゴリズムで、最もよく使われている手法が協調フィルタリングです。Amazonのサイトを見ていると、「この商品を買った人はこんな商品も買っています」と、似たような商品が紹介されている経験をされている方は多いでしょう。
これは、サイト訪問者と似た行動履歴を持つ別のユーザーの購買履歴などを基に、サイト訪問者が購入する可能性が高い商品を表示する仕組みで、協調フィルタリングによるレコメンドシステムの例です。
協調フィルタリングによるレコメンドには大きく分けて、アイテムベースレコメンドとユーザーベースレコメンドがあるので、それぞれを紹介します。
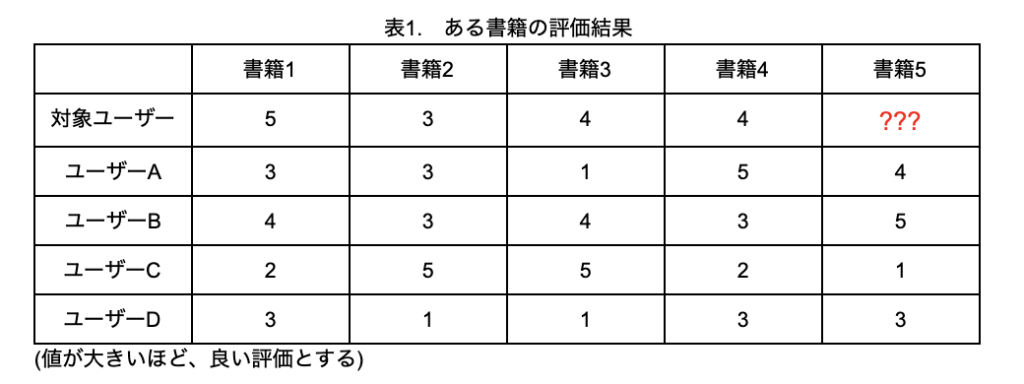
レコメンデーションシステムでは、ユーザーとアイテムのマトリックスデータが必要となります。例えば、書籍で5段階評価を行っているとしましょう。対象ユーザーは書籍5を読んでいないため評価していませんが、どのような評価をすると予測できるでしょうか。もし高い評価をすると予想できるのであれば、書籍5をレコメンドすれば買ってもらえる可能性が高まります。
1) ユーザーベースレコメンド
ユーザーベースレコメンドは、対象ユーザーの行動分析を基に他のユーザーに対する類似度を算出し、類似度が高いユーザーが分かると、その類似ユーザーが購入した商品を対象ユーザーにレコメンドするしくみです。
表1の場合、対象ユーザーが評価している書籍1~4について、似ている評価をしている類似ユーザーを見つけ出し、その類似ユーザーの書籍5に対する評価実績をもとに、対象ユーザーの書籍5を予測することができます。これがユーザーベースレコメンドと呼ばれるアルゴリズムです。ユーザーの類似度を求める際は、ピアソンの相関係数がよく使われています。
では、Pythonを用いてユーザーベースの協調フィルタリングで、対象ユーザーの書籍5の評価値を予測してみましょう。
後の計算を考えると、初めからNumpy配列でデータベースを作った方が楽ですが、実務ではDataframe形式でデータを入手できることの方が多いので、初めのデータベースはあえてPandasで作成しました。
import numpy as np
import pandas as pd
#データベースの作成。未評価のアイテムは-1とする。
data = {"書籍1": [5, 3, 4, 2, 3],
"書籍2": [3, 3, 3, 5, 1],
"書籍3": [4, 1, 4, 5, 1],
"書籍4": [4, 5, 3, 2, 3],
"書籍5": [-1, 4, 5, 1, 3]}
df = pd.DataFrame(data, index=["対象ユーザー", "ユーザーA", "ユーザーB", "ユーザーC", "ユーザーD"], dtype="float32")
#評価値をNumpy配列に変換
eval = df.to_numpy()
#書籍間の相関係数を計算し、(書籍のインデックス, 類似度)のタプルリストを返す関数
def corr_coefficient(points, user_index):
similarities_corr = []
target = points[user_index]
for i, score in enumerate(points):
indices = np.where(((target+1) * (score+1)) != 0)[0]
if i == user_index:
continue
else:
similarity = np.corrcoef(target[indices], score[indices])[0, 1]
similarities_corr.append((i, similarity))
#類似度の大きい順に返す
return sorted(similarities_corr, key=lambda s: s[1], reverse=True)類似度を算出する関数ができたので、対象ユーザーについて類似度を見てみましょう。
user_index = 0 # 0番目のユーザ
print(corr_coefficient(eval, user_index))
similarities = corr_coefficient(eval, user_index)[(2, 0.7071067811865476), (4, 0.7071067811865476), (1, 0.0), (3, -0.7071067811865475)]対象ユーザーは、ユーザーB及びユーザーDと類似していることがわかりました。
次に、ユーザーの類似度から評価値を予測する関数を作りましょう。
# 評価値を予測する関数
def predict(points, similarities, target_userindex, target_itemindex):
target = points[target_userindex]
ave_target = np.mean(target[np.where(target >= 0)])
bunshi = 0.0
bunbo = 0.0
k = 0
for ruijido in similarities:
# 類似度の上位2人の評価値を使う
if k > 2 or ruijido[1] <= 0.0:
break
score = points[ruijido[0]]
if score[target_itemindex] >= 0:
bunbo += ruijido[1]
bunshi += ruijido[1] * (score[target_itemindex] - np.mean(score[np.where(score >= 0)]))
k += 1
return ave_target + (bunshi / bunbo)これで、ユーザーベースで評価値を予測するモデルができたので、表1の対象ユーザーの書籍5の評価値を予測してみます。
points = eval
target_userindex = 0
target_itemindex = 4
predict(points, similarities, target_userindex, target_itemindex)
5.0
評価値は5.0と予測できました。
2) アイテムベースレコメンド
アイテムベースレコメンドは、訪問ユーザーの行動分析を基に商品同士の類似度を算出し、商品Aを購入したユーザーが商品Bも購入しやすいと分かると、商品Aを購入したユーザーに対して商品Bをレコメンドするしくみです。
表1の場合、対象ユーザー以外のユーザーA~Dが評価している書籍1~5の評価値から、書籍間の類似度を算出し、類似度行列を作ります。対象ユーザーの書籍1~4の評価値と類似度行列の積から、書籍5に評価値を予測でき、予測値が大きければ書籍5をレコメンドできます。これがアイテムベースレコメンドと呼ばれるアルゴリズムです。アイテムの類似度を求める際は、コサイン類似度がよく使われています。
では、アイテムベースの協調フィルタリングで、対象ユーザーの書籍5の評価値を予測してみましょう。
import numpy as np
import pandas as pd
#Pandasでデータベースの作成
data = {"書籍1": [3, 4, 3, 1],
"書籍2": [1, 3, 3, 5],
"書籍3": [2, 4, 1, 5],
"書籍4": [3, 3, 5, 2],
"書籍5": [3, 5, 4, 1]}
df = pd.DataFrame(data, index=["ユーザーA", "ユーザーB", "ユーザーC", "ユーザーD"], dtype="float32")
#評価値をNumpy配列に変換
eval = df.to_numpy()
#書籍間のコサイン類似度を計算し、(書籍のインデックス, 類似度)のタプルリストを返す関数
def cos_similarities(points, item_index):
similarities_cos = []
books = points.transpose()
target_item = books[item_index]
for i, item in enumerate(books):
if i == item_index:
similarity=1
else:
similarity = np.dot(target_item, item.T) / (np.linalg.norm(target_item) * np.linalg.norm(item))
similarities_cos.append((i, similarity))
return similarities_cos
#類似度順にして返したいときは、returnを以下に変更
#return sorted(similarities_cos, key=lambda s: s[1], reverse=True)コサイン類似度で書籍間の類似度を計算する、cos_similaritiesという関数を作っています。書籍1と他の書籍の類似度を見たいときは、以下のように見ることができます。
cos_similarities(eval, 0)[(0, 1), (1, 0.83149713), (2, 0.7916331), (3, 0.946497), (4, 0.9767684)]アイテムベースのレコメンドシステムの場合、以下のような類似度行列を作っておくことで、新しいユーザーに対しても、新たに類似度を計算する必要がないので、素早くレコメンドできるメリットがあります。
#類似度行列の作成
ruijido_gyoretu = []
for i in range(eval.shape[1]):
for j in range(eval.shape[1]):
ruijido_gyoretu.append(cos_similarities(eval, i)[j][1])
ruijido_gyoretu=np.array(ruijido_gyoretu).reshape(eval.shape[1],eval.shape[1])
print(ruijido_gyoretu)[[1. 0.83149713 0.79163313 0.94649702 0.97676837]
[0.83149713 1. 0.94259095 0.81362903 0.73885053]
[0.79163313 0.94259095 1. 0.66732609 0.6833303 ]
[0.94649702 0.81362903 0.66732609 1. 0.93955845]
[0.97676837 0.73885053 0.6833303 0.93955845 1. ]]書籍1と書籍5の類似度は0.977であることが分かります。
最後に、類似度行列を使って評価値を予測する関数を作ります。
def predict(u, sims):
# 未評価は0, 評価済は1となるベクトル。分母の計算に使用。
x = np.zeros(u.size)
x[u > 0] = 1
bunshi = sims.dot(u)
bunbo = sims.dot(x)
prediction = np.zeros(u.size)
for i in range(u.size):
# 分母が 0 になるケースと評価済アイテムは予測値を 0 とする
if bunbo[i] == 0 or u[i] > 0:
prediction[i] = 0
else:
prediction[i] = bunshi[i] / bunbo[i]
# ユーザ u のアイテム i に対する評価の予測
return predictionこれで、アイテムベースで予測するモデルができたので、表1の対象ユーザーの書籍5の評価値を予測してみます。
u = np.array([5, 3, 4, 4, 0])
sims = ruijido_gyoretu
predict(u, sims)すでに評価しているアイテムに対してはその評価値を、未評価のアイテムは0を入力すると、以下の結果が得られます。
array([0. , 0. , 0. , 0. , 4.07126473])対象ユーザーの書籍5の評価値は4.07と予測できました。
ユーザーベースにしろアイテムベースにしろ、予測値が得られればあとは、その予測値が各々で設定した基準値より大きければ、対象ユーザーに書籍5をレコメンドすると購入してもらえる可能性が高いと期待できます。
協調フィルタリングのメリットとデメリット
ユーザーベースレコメンドとアイテムベースレコメンドを合わせて、協調フィルタリングと言いますが、協調フィルタリングには、以下のようなメリットとデメリットがあります。
1) 協調フィルタリングのメリット
・他のユーザーの実績を通じてレコメンドされるため、対象者がこれまで全く興味の無かった商品も紹介することができます。
・たとえ対象アイテムについての知識が全くなくても、他のユーザーの実績を通じてレコメンドすることができます。
2) 協調フィルタリングのデメリット
・誰も評価していないアイテムは評価することができず、レコメンドできません。
・そのアイテムの利用者が少ない場合、類似したアイテムを精度よく予測できないため、レコメンドの精度が悪くなります。
初期の評価できない、あるいは、精度が悪い問題を、コールドスタート問題と言います。
3. おわりに
今回はAmazonなどでも用いられている、協調フィルタリングについてみてきました。協調フィルタリングには、ユーザーベースレコメンドとアイテムベースレコメンドの2種類がありますが、アイテムベースであればいったん類似度行列を作ってしまえば、新規ユーザーにもそのまま適用することができます。従って、アイテム数が多い場合はアイテムベースレコメンドの方が、素早くレコメンドすることができます。
4. 参考サイト
第1回 レコメンデーションとは
レコメンドで使われる4つのアルゴリズムを簡単に紐解く!
レコメンドに用いられる協調フィルタリングの利点と欠点とは?
協調フィルタリング入門
piponではエンジニアの皆様に業務委託や副業でAI・データサイエンスの案件をご紹介しています!
piponの案件にご興味がある方は以下のフォームにご登録ください。案件をご案内します。 https://share.hsforms.com/1qk0uPA_lSu-nUFIvih16CQegfgt