
解析の目的
新型コロナウイルスの流行により、MRの活動様式に変化がありました。今までは医師の所へ直接出向き、薬の説明をしたりしていましたが、医師との直接的なコンタクトが難しくなり、オンラインでの活動が増えました。
そこで製薬会社各社はWebカンファレンスに力を入れ始めています。Webカンファレンスを開催するにあたって、集客は他社に依頼することが一般的なようです。そしてその集客にはコストがかかります。コストをかければかけるほど一般的には多くの医師が参加する大規模なWebカンファレンスになりますが、はたしてどれくらいのコストをかければよいのかは不明です。そこで今回は、Webカンファレンスの参加人数およびその他のMRの活動と、売上との関係を分析しました。
具体的には、例えばMRの活動での医師への直接的なコンタクトを取り上げると、コンタクトを取れば取るほど売上に直結するわけではなく、医師へのコンタクトの売上への影響は回数を重ねるにつれて頭打ちになってくることが想像できます。Webカンファレンスにも同様なことが言えるのではないかという仮定の下、多くのMR活動について回数を重ねるとその影響は頭打ちになるだろうという事前知識を解析に反映させ、解析結果を用いてMRの活動はどのくらいの回数にするのが良いのだろうかといったことを知るのが解析の目的になります。
使用したデータ
今回の解析には、ある薬の売上(正確には処方日数)やWebカンファレンスの参加人数、説明会の開催回数や医師への直接的なコンタクト回数といったMRの活動をデータとして用意しました。Webカンファレンスの参加人数や説明会の開催回数、医師への直接的なコンタクト回数といった説明変数から、ある薬の売上(被説明変数)を説明するとともに、売上への説明変数の影響が、例えば医師への直接的なコンタクト回数を増やすにつれてどう変化するのかを調べることが今回の解析の目的になります。
また、新型コロナウイルスの流行前と流行後とでは、Webカンファレンスの様態やMRの活動がガラリと変わっていることが予測されます。したがって新型コロナウイルス流行前と流行後のデータを切り離し、流行後のデータだけで解析するのが自然です。しかしそのようにすると、解析に用いることのできるデータが確保できたのはコロナ禍におけるある2ヶ月だけになってしまい、データ量としてはかなり少なくなってしまいました。そこで月×病院という単位でデータ量を膨らませることにしました。全国には数千・数万という医療施設があるため、月×病院という単位のデータにすることで、データ量を確保しました。
ここで、「解析の目的」ではWebカンファレンスにかけるコストの最適化を目的としていましたが、実際の解析では実際にかかったコストではなく、Webカンファレンスに参加した医師の人数をデータとして用いています。これは、あるWebカンファレンスを開催するにあたってかかったトータルのコストは分かるものの、医療施設ごとにいくらコストがかかったかがデータとしては手に入らないためです。しかし、一般にWebカンファレンスの開催にかかるコストと参加人数には強い相関があることが分かっているため、コストの代わりに参加人数を解析に用いました。
モデル
以下の論文のモデル(Media Mix Model, MMM)を応用したものを使用しました:
Jin et al., 2017. Bayesian methods for media mix modeling with carryover and shape effects.
具体的には、線形回帰モデルを構築する際に、それぞれの説明変数をある関数で変換したものを使用します。上記の論文ではヒルの式と呼ばれる関数で説明変数を変換しています。この変換に使用する関数はパラメータをもっており、このパラメータを推定することで、被説明変数への説明変数の影響がどのように変換するかを推定することができます。
しかし、上記の論文を検証した人が数名おり、Webの記事にもなっていますが、MCMC(学習)が収束しなかったり、していても想定していた真の値から外れていたりと、色々と問題のあるモデルであるようです。我々はこの原因を、ヒルの式があまりに柔軟すぎるからであると考えました。したがって、今回の解析ではヒルの式を用いるのではなく、関数の形がある程度決まっているような別の関数を使用しました。説明変数を変換する関数を選択する際には、「説明変数の値が大きくなればなるほど、被説明変数への影響は頭打ちになるだろう」という事前知識を反映するような関数を選択しました。今回は説明変数を関数Aで変換した場合のモデルと、関数Bで変換した場合のモデルとで2種類のモデルを構築しました。
モデルの評価
モデル選択は対数尤度によるデータを当てはまり具合と、推定された説明変数を変換する関数の形を見て、総合的に判断しました。
説明変数を変換する関数は、例えば以下のように推定されます(Jin et al. 2017より)。
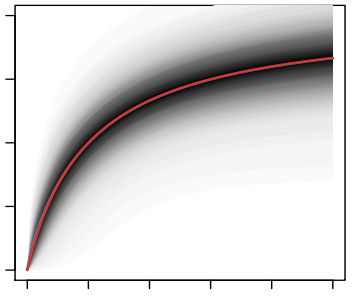
横軸が説明変数の値、縦軸がその説明変数が被説明変数に与える影響です。例えば、横軸がMRの医師への直接的なコンタクト回数、縦軸が売上だとします。すると最初のうちは医師へコンタクトをとると売上が上がっていきますが、その売上への影響は医師へのコンタクト回数が増えるにつれて減衰していっているのが分かります。Webカンファレンスに対しても同様です。このように各説明変数に対して、推定された変換関数の形をみながらクライアントの方々とディスカッションを行い、構築した2つのモデルのうちどちらが良いかを判断しました。今回の場合は2つともデータへの当てはまりはあまり変わらなかったため、2つのモデルを比べてデータの当てはまりが悪い方でしたが結果の解釈がしやすい方のモデルを最終モデルとして選択しました。
最終的にこの結果を用いて、Webカンファレンスには1施設あたり○○人くらい呼ぶのが良く、そのためには△△円くらい集客に投資すればよい、といったような分析ができます。

